A Survey of Vibe Coding
with Large Language Models
Vibe Coding is the emerging practice of building software by validating AI-generated implementations through outcome observation rather than line-by-line code comprehension. This survey gives Vibe Coding its first formal definition as a constrained Markov decision process over a Human–Project–Agent triad, then consolidates the entire ecosystem — code LLMs, coding agents, development environments, feedback loops, and five composable development models — into a single research-grade taxonomy.
Abstract #
The advancement of large language models (LLMs) has catalyzed a paradigm shift from code-generation assistance to autonomous coding agents, enabling a novel development methodology termed Vibe Coding — where developers validate AI-generated implementations through outcome observation rather than line-by-line code comprehension. Despite its transformative potential, the effectiveness of this emergent paradigm remains under-explored, with empirical evidence revealing unexpected productivity losses and fundamental challenges in human–AI collaboration.
To address this gap, this survey provides the first comprehensive and systematic review of Vibe Coding with large language models, establishing both theoretical foundations and practical frameworks. Drawing from systematic analysis of over 1,000 research papers, we survey the entire vibe coding ecosystem, examining critical infrastructure components including LLMs for coding, LLM-based coding agents, the development environment of coding agents, and feedback mechanisms. We first introduce Vibe Coding as a formal discipline by formalizing it through a Constrained Markov Decision Process that captures the dynamic triadic relationship among human developers, software projects, and coding agents. Building upon this theoretical foundation, we then synthesize existing practices into five distinct development models: Unconstrained Automation, Iterative Conversational Collaboration, Planning-Driven, Test-Driven, and Context-Enhanced Models, thus providing the first comprehensive taxonomy in this domain. Critically, our analysis reveals that successful Vibe Coding depends not merely on agent capabilities but on systematic context engineering, well-established development environments, and human–agent collaborative development models.
TL;DR
Vibe Coding ≠ trusting AI blindly. It is an engineering discipline.
- Triadic system $\mathcal{V}=\langle\mathcal{H},\mathcal{P},\mathcal{A}_\theta\rangle$ — Humans govern what / why, Projects define where, Agents manage how.
- Five composable workflows: UAM, ICCM, PDM, TDM, CEM — selected by risk, speed, and governance needs.
- Context engineering, executable feedback loops, and well-bounded sandboxes — not raw model quality — determine long-horizon success.
- Open challenges: cascading errors, dependency proliferation, alignment failures, and the need for scalable weak-to-strong oversight.
1 · Introduction #
Large language models (LLMs) have significantly advanced artificial intelligence through conversational systems capable of fluent natural-language understanding and generation. Early adoption in software development positioned LLMs as supplementary assistants — developers employed natural-language prompts to generate code snippets, but significant accuracy limitations necessitated manual review and iterative debugging throughout the software development lifecycle.
The emergence of advanced architectures like GPT-4 and Claude Sonnet 4 enabled qualitative improvements, leading to Coding Agents capable of autonomously completing programming tasks through dynamic environmental interaction via shell commands, file operations, and test execution. Progress on real-world benchmarks has been rapid; on SWE-bench, SWE-agent reached 12.5% with custom interfaces, AutoCodeRover achieved 19.0%, Agentless 27.3%, OpenHands 53% on SWE-bench Verified, and self-improving agents demonstrated 17–53% performance gains on SWE-bench Verified.
With the advancement of models such as GPT-5 Pro and Claude Sonnet 4.5, agent capabilities have achieved significant breakthroughs, giving rise to “Vibe Coding” — a paradigm where developers rely on AI-generated code without line-by-line inspection, engaging instead in iterative cycles of natural-language requirement articulation, execution observation, and feedback. Coding Agents go beyond code generation: they autonomously configure environments, execute programs, self-diagnose errors, and update implementations. This represents a substantial elevation in human trust and a departure from traditional comprehension mandates toward outcome-oriented validation.
However, possessing powerful agents proves insufficient. Task complexity exposes fundamental limitations in unstructured natural-language instructions, which fail to convey nuanced requirements and architectural constraints. Empirical evidence reveals that experienced developers using Cursor with Claude experienced a 19% increased completion time rather than anticipated productivity gains. Effective human–AI collaboration demands systematic prompt and context engineering, structured instructions, and balanced agency distribution across distinct interaction types.
To address this gap, this survey provides the first comprehensive and systematic review of Vibe Coding. We introduce Vibe Coding as a dynamic triadic relationship among human developers, software projects, and coding agents, providing its first formal definition as an engineering discipline through a Constrained Markov Decision Process. Building on this foundation, we distill Vibe Coding workflows into five development models — UAM, ICCM, PDM, TDM, CEM — representing the first comprehensive synthesis of existing practices.
3 · Vibe Coding: The Engineering of Managing Coding Agents #
3.1 Definition of Vibe Coding
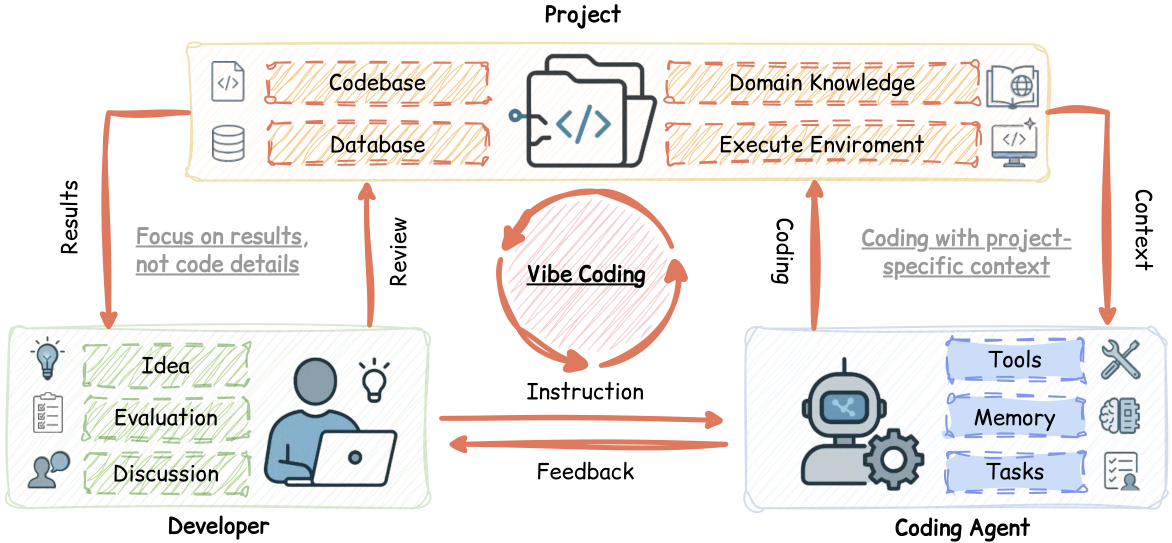
We define Vibe Coding as an engineering methodology for software development grounded in large language models. At its core, as shown in Figure 1, it represents a dynamic triadic relationship among human developers, software projects, and Coding Agents. In this paradigm, humans evolve from direct code authors into intent articulators, context curators, and quality arbiters. Projects extend beyond static code repositories to become multifaceted information spaces encompassing codebases, databases, and domain knowledge. Coding Agents, as intelligent executors, perform code generation, modification, and debugging under the dual guidance of human intent and project constraints.
Formalization of the Triadic Relationship
We model Vibe Coding as a dynamic interactive system defined by the triple $\mathcal{V} = \langle \mathcal{H}, \mathcal{P}, \mathcal{A}_\theta \rangle$, where:
- $\mathcal{H}$ — Human developer, equipped with requirement-cognition capability $\mathcal{H}_{\text{req}}: \mathcal{D} \to \mathcal{I}$ and quality-discrimination capability $\mathcal{H}_{\text{eval}}: \mathcal{O} \to \{0,1\} \times \mathcal{F}$.
- $\mathcal{P}$ — Software project, represented as a context space $\mathcal{P} = \langle \mathcal{C}_{\text{code}}, \mathcal{C}_{\text{data}}, \mathcal{C}_{\text{know}} \rangle$.
- $\mathcal{A}_\theta$ — Coding Agent, a large language model parameterized by $\theta$, executing the conditional generation function $\mathcal{A}_\theta: \mathcal{I} \times \mathcal{P} \times \mathcal{E} \to \mathcal{O}$.
The collaboration is modeled as a Constrained Markov Decision Process:
where the state space $\mathcal{S}_{\mathcal{P}}$ is defined by the project's current state, the action space $\mathcal{A}_{\mathcal{H} \to \mathcal{A}_\theta}$ is triggered by human instructions to agent behaviors, the transition function $\mathcal{T}_{\mathcal{A}_\theta \mid \mathcal{P}}$ is constrained by project specifications, $\mathcal{R}_{\mathcal{H}}$ is determined by human evaluation, and $\gamma$ is the discount factor.
Agent's Conditional Generation Process
Given human intent $\mathcal{I}$, project context $\mathcal{K} \subseteq \mathcal{P}$, and execution environment $\mathcal{E}$, the agent generates code $Y=(y_1,\dots,y_T)$ in an autoregressive manner:
where $\mathcal{C}_t = \mathcal{A}(\mathcal{I},\mathcal{K},\mathcal{E},y_{ The core challenge of Vibe Coding is finding optimal context-orchestration strategies
$\mathcal{F}^* = \{\mathcal{A},\text{Retrieve},\text{Filter},\text{Rank}\}$
maximizing generation quality within a context window $L_{\max}$: Let the agent produce output $o_k \in \mathcal{O}$ at iteration $k$. The human supervision function
returns an acceptance subset $\mathcal{A}_k \subseteq o_k$ and a correction signal $\delta_k$: The task evolution trajectory is an instruction-set sequence $\{\mathcal{I}_0,\mathcal{I}_1,\dots,\mathcal{I}_K\}$
satisfying monotonicity $\mathcal{I}_k \subseteq \mathcal{I}_{k+1}$: This formalizes the multi-stage optimization: Key insight
Humans govern “What” (defining the right problems, allowing them to evolve) and “Why”
(judging solution appropriateness); Projects define “Where” (constraining solution-space boundaries);
Agents manage “How” (exploring technical implementation pathways). The synergy of these three
entities constitutes a self-adaptive, requirement-evolvable closed-loop software development system. Vibe Coding transforms software development from passive assistance to collaborative partnerships,
addressing challenges in democratization, workflow efficiency, and ecosystem expansion. Production applications traditionally require coordinating frontend, backend, database, security,
DevOps, and QA specialists with substantial overhead. Coding agents provide diverse expertise across
domains; developers focus on requirements while agents implement across stacks. Individual developers
now implement cloud infrastructure and performance optimizations without formal training, compressing
prototypes from weeks to days. Vibe Coding aims to balance development velocity and code quality — historically conflicting
objectives. Agents sustain 24/7 operation: automated testing, refactoring, and performance profiling.
Automating mechanical tasks liberates cognitive resources for design and optimization, while agents
enable exhaustive exploration through rapid iteration with human oversight validating architectural
decisions. Vibe Coding democratizes development by lowering technical barriers. Natural language becomes the
primary creation interface. Domain experts — medical practitioners, educators, designers — articulate
needs without computer-science education. Economic impact manifests through creator-economy expansion:
domain experts monetize specialized tools without technical co-founders, paralleling previous
democratization waves.
Optimization Objective
Human–Agent Collaborative Loop and Task Evolution
Formalization of Iterative Task Expansion
3.2 Why Vibe Coding
Team-Scale Capabilities for Individual Developers
Continuous Development and Quality Convergence
Broadening the Software Creator Ecosystem
4 · Large Language Models for Coding #
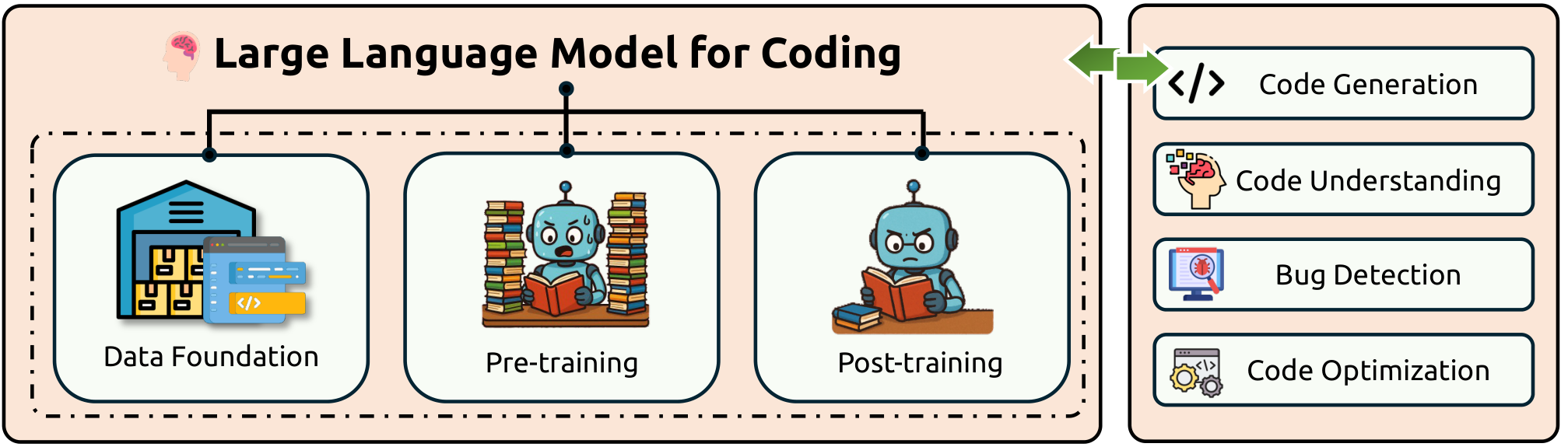
4.1 Data Foundation of Code LLMs
Pre-training Code Corpora
Code LLMs require large-scale training data from diverse sources, primarily sourced from open platforms like GitHub and Stack Overflow, with quality filtering based on repository stars, documentation, and community engagement. Two strategies emerge: depth-focused (concentrate on popular languages for quality) and breadth-focused (span diverse languages for coverage).
The Stack dataset uses the depth-focused approach with 3.1 TB of permissively licensed code across 30 languages. The Stack v2 expands coverage to 67.5 TB across 619 programming and markup languages. GPT-Neo uses diverse mixed corpora including The Pile; CodeLlama employs SlimPajama’s 627B tokens paired with The Stack; Arctic-SnowCoder uses a filtered combination of 400B tokens. Data quality has driven sophisticated processing — RefineCode applies 130+ language-specific filtering rules across 607 languages, and SwallowCode implements four-stage pipelines for syntax validation, quality assessment, deduplication, and LLM-based rewriting.
Instruction & Preference Datasets
Instruction datasets compile permissively licensed source-code repositories and synthetically constructed data. Notable: CommitPack (2 GB filtered from 4 TB of commit-message pairs), OpenCodeInstruct (5M samples), SynCode-Instruct (≈20 B synthetic tokens). For preference learning, CodeUltraFeedback provides 10 k instructions with 4 responses each evaluated by GPT-3.5; the PLUM framework employs GPT-4-generated unit tests for functional-correctness-based ranking.
Construction methodologies evolved from costly human annotation to scalable synthesis: Self-Instruct bootstraps from seeds; Evol-Instruct progressively increases complexity; OSS-Instruct integrates real open-source snippets as seeds. Nvidia’s Nemotron-4 achieves SoTA performance using 98% synthetically generated alignment data.
4.2 Pre-training Techniques
Code LLMs leverage transfer-learning paradigms inherited from BERT and GPT, with pre-training on large-scale unlabeled data before task-specific fine-tuning. Code-specific objectives surpass traditional masked language modeling: GraphCodeBERT’s data-flow prediction captures semantic relationships; CodeT5 and DOBF use variable-naming tasks leveraging language structure.
- Masked LM dominant for code understanding (CodeBERT, GraphCodeBERT).
- Autoregressive LM foundation for code generation; CodeGPT and CodeLlama add fill-in-the-middle.
- Denoising for encoder–decoder (PLBART, CodeT5+) via span-level reconstruction.
- Structure-aware objectives over ASTs, control-flow and data-flow graphs.
- Contrastive learning (UniXcoder, ContraCode) and multimodal pre-training (bimodal NL/PL).
Continual Pre-training Strategies
CPT enables broad-corpus pre-trained models to acquire domain knowledge while preserving foundational capabilities. CodeLlama leverages CPT on LLaMA2; DeepSeek-Coder-V2 continues from DeepSeek-V2 with 6 T extra tokens. Qwen2.5-Coder determined an optimal 7:2:1 mixing ratio for code, text, and mathematics yielding 20%+ improvement vs. code-only training. To prevent catastrophic forgetting, DeepSeek replays 30% of original pre-training data. Open problems include the “stability gap” at the onset of new domain training, and CPT difficulty with limited-token corpora.
4.3 Post-training Techniques
Supervised Fine-Tuning
SFT enhances LLM capabilities while aligning behavior with human expectations, using curated labeled examples. Instruction tuning improves zero-shot performance on unseen tasks; PEFT (LoRA, adapters) make fine-tuning tractable for very large models. Critically, recent work (AlpaGasus, LIMA) shows data quality dominates quantity: 9,000 curated samples can beat much larger noisy datasets, and SFT on high-quality demonstrations can outperform preference fine-tuning on coding tasks.
Reinforcement Learning
RL has become pivotal: RLHF aligns behavior using human-preference rewards (InstructGPT); DPO replaces the RL stage with classification-style preference optimization; GRPO incorporates group-wise comparative feedback; Reinforcement Learning with Verifiable Rewards (RLVR) replaces learned reward models with deterministic rule-based rewards — particularly effective for coding and mathematics where correctness can be objectively verified. CodeRL pioneered actor–critic with learned correctness reward; PPOCoder integrates compiler/test feedback; StepCoder uses curricula over completion subtasks. Domain-specific applications include VeriSeek for Verilog generation.
Persistent challenges: training instability (catastrophic forgetting, reward hacking), scale dependence (benefits primarily at 8B–670B parameters), and objective mismatch between expected cumulative reward and risk-seeking Pass@k metrics.
5 · LLM-based Coding Agent #
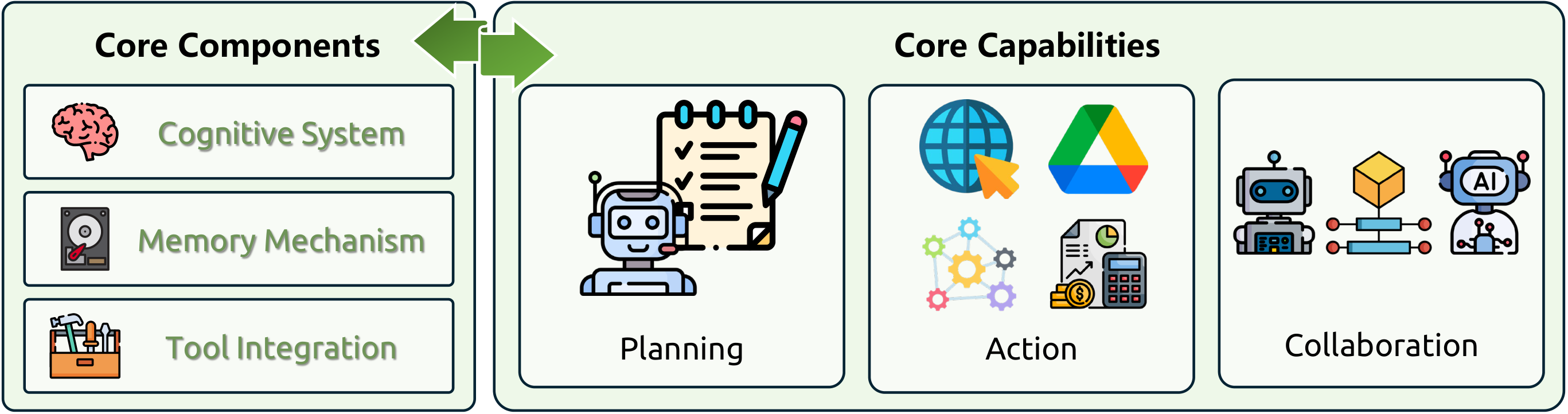
5.1 Decomposition and Planning Capability
Task Decomposition Strategies
Task decomposition systematically breaks complex problems into manageable subtasks. Strategies have evolved into distinct paradigms: factored cognition for simultaneous processing, process supervision for sequential dependencies, Chain-of-Thought for step-by-step reasoning, and extensions like Tree-of-Thought (ToT) and Graph-of-Thought for multi-path reasoning. Concrete techniques include few-shot or zero-shot CoT, Auto-CoT (clustering-based sample generation), Plan-and-Solve, and HyperTree Planning with Monte-Carlo integration.
Plan Formulation Methods
Three paradigms have emerged: LLM-as-Planner using inherent reasoning, LLM-as-Facilitator translating to PDDL, and Multi-Agent Planning. Planning with feedback uses ReAct interleaving Thought/Action/Observation; Reflexion adds Evaluator, Self-reflection, and memory buffers for continual improvement. Integrated approaches combine structured PDDL planners (Fast Downward) with LLM sub-task allocation.
Persistent challenges: goal decomposition into actionable steps, long-horizon task management, and training-data scarcity requiring synthetic augmentation.
5.2 Memory Mechanism
Overview and Fundamentals
Contemporary architectures map context and parameters to short-term and long-term memory, transforming contextual knowledge into parameter updates. Short-term memory corresponds to in-context information; long-term memory stores info over days to years, split into declarative (explicit) and non-declarative (implicit). Implementations classify into parametric (in weights) and non-parametric (external systems).
| Coding Agent | Code Search | File Ops |
Shell | Web Search | Testing | MCP | Multi- modal | Context |
|---|---|---|---|---|---|---|---|---|
| CodeAgent | ✓ | ✓ | — | ✓ | ✓ | — | — | ✓ |
| MapCoder | ✓ | — | — | — | ✓ | — | — | ✓ |
| ChatDev | — | — | — | — | ✓ | — | — | ✓ |
| CodeAct | — | — | ✓ | — | ✓ | — | — | — |
| SWE-Search | ✓ | ✓ | — | — | ✓ | — | — | ✓ |
| OpenHands | — | ✓ | ✓ | ✓ | ✓ | — | — | ✓ |
| OpenHands-Versa | — | ✓ | ✓ | ✓ | ✓ | — | ✓ | ✓ |
| MetaGPT | — | ✓ | ✓ | ✓ | ✓ | — | — | ✓ |
| SWE-agent | ✓ | ✓ | ✓ | — | ✓ | — | — | ✓ |
| AutoCodeRover | ✓ | — | — | — | ✓ | — | — | ✓ |
| Lita | ✓ | ✓ | ✓ | — | ✓ | — | — | ✓ |
| RepoForge | — | ✓ | ✓ | — | ✓ | — | — | ✓ |
| Code2MCP | — | — | — | — | ✓ | ✓ | — | ✓ |
| ScreenCoder | — | — | — | — | — | — | ✓ | ✓ |
| Cursor IDE | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Claude Code | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Gemini Code CLI | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Qwen Coder | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Codex | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Memory Operations and Architecture
Memory operations are managed through six fundamental procedures: consolidation, indexing, updating, forgetting, retrieval, and compression. Short-term memory enables hierarchical immediate-feedback integration (FALCON two-level; MemTool 90–94% efficiency). Long-term memory uses external storage — vector databases (RecallM, Memorizing Transformers), Memory Bank with Ebbinghaus-inspired forgetting curves, and three architectural patterns: Long-Context Agents (FIFO), RAG Agents, and Agentic Memory Agents. Frameworks like RAISE and InfiniteICL adopt dual-component systems mirroring human cognition; Think-in-Memory caches intermediate reasoning, MemGPT extends effective context via virtual paging.
5.3 Action Execution
Tool Invocation
Tool integration with LLMs has transformed AI-powered development. ReAct established observation-action-thought as the foundation for LangChain and AutoGen. Modern frameworks adopt standardized paradigms and automatically transform documentation into callable functions. Executable code-based frameworks (CodeAct, MapCoder) consolidate actions into a unified Python space enabling dynamic revision and composition, with substantial improvements over JSON-only constraints. The Model Context Protocol standardizes schema-driven interfaces and discovery mechanisms (ScaleMCP) for large-scale tool repositories.
Code-Based Action Implementation
Contemporary systems follow five-stage processes: planning, selection, parameter extraction, invocation, result integration. CodeAct integrates Python interpreters for dynamic multi-turn revision; CodeAgent extends from isolated snippets to complex projects with intricate dependencies; AgentCoder’s programmer / test designer / executor agents achieve superior performance with reduced computational overhead. Repository-scale evolution systems demonstrate autonomous improvement across hundreds of files. RLEF enables learning optimal strategies through policy optimization mirroring human preferences. KnowCoder pioneered Python class-based schema representations for unified information extraction.
5.4 Reflection: Iteration, Validation, and Debugging
Iterative Refinement
Effective code generation requires systematic refinement beyond single attempts. Multi-round frameworks employing iterative refinement significantly improve synthesis quality, enabling LLMs to learn from errors through reflection mechanisms incorporating failed tests. Modern frameworks employ multi-agent architectures with coder and critic agents in iterative loops; sophisticated systems implement Reflection / Thinking / Execution Agent roles.
Code Validation & Intelligent Debugging
Code validation evolved into multi-layered approaches using dedicated critic agents focusing on efficiency and functional correctness. LLM-as-a-Judge frameworks produce ratings and repair feedback. Self-debugging splits into post-execution (analyse after running) and in-execution (examine intermediate states; LDB), the latter showing more promise. Industrial deployment: Meta’s TestGen-LLM achieves 75% building correctly, 57% passing reliably, 25% increasing coverage. Some frameworks reach 98.2 on HumanEval through debugging mechanisms decomposing failed code via Control Flow Graph analysis.
5.5 Agent Collaboration
Collaboration Mechanisms
Multi-agent systems distribute responsibilities, improving scalability, resilience, and adaptation. Communication is the cornerstone — four primary architectures emerge: layered, decentralized, centralized, and shared message pools. Role-based collaboration assigns expert roles through pipeline, group-discussion, or hybrid combinations (AutoGen, CrewAI).
Framework Implementations
MetaGPT implements standard operating procedures through role-specific prompts; ChatDev uses chat-chain modeling of a virtual software company; CAMEL enables autonomous cooperation through role-playing. MapCoder achieves SoTA: 93.9% HumanEval, 83.1% MBPP, 22.0% APPS, 28.5% CodeContests, 45.3% xCodeEval. ChatDev's communicative agents are cost-effective and capable of proactively addressing errors by mimicking human teamwork patterns.
6 · Development Environment of Coding Agent #
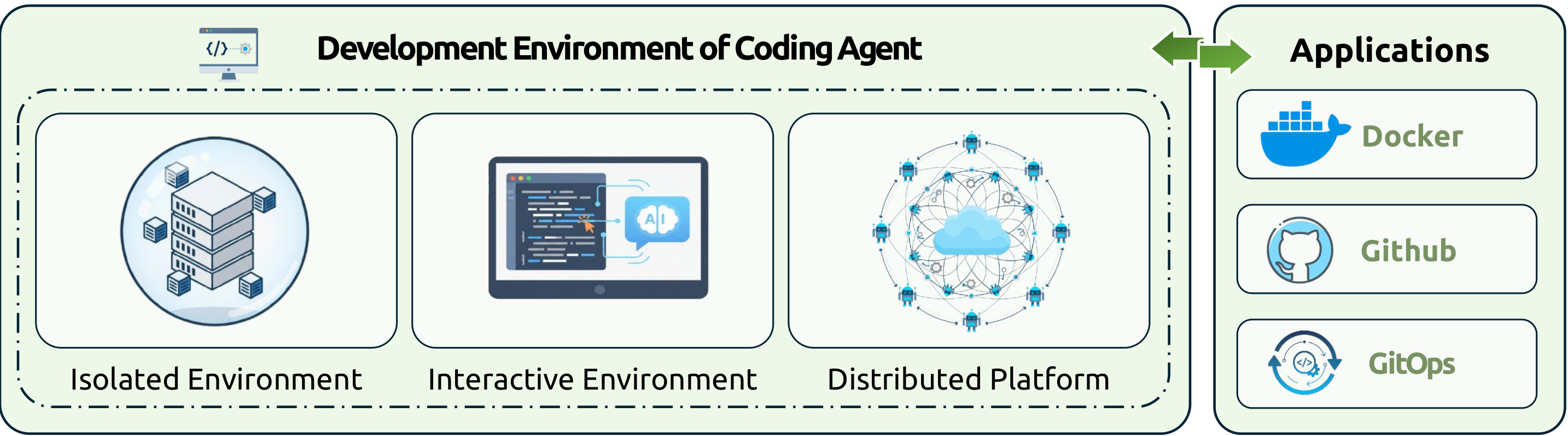
6.1 Isolated Execution Runtime Environment
Containerization Technologies
Containerization guarantees consistent execution across diverse hardware and operating systems. Docker remains dominant; LXC/LXD and research sandboxes (SandboxFusion, MPLSandbox) provide stronger isolation or multi-language support. Kubernetes assigns coding-agent tasks into isolated pods, allocates computational quotas, and enforces automatic timeouts to prevent resource monopolization.
Security Isolation Mechanisms
Sandbox-based systems provide first-line defense limiting privileges of agent-executed code. gVisor intercepts system calls for fine-grained policies; lightweight hypervisors and microkernels enhance host/container separation. Multi-layer frameworks (SAFE-LLM, NatiSand) combine container isolation with dynamic monitoring. Hardware-assisted techniques include Intel PKRU and ARM TrustZone. WebAssembly engines provide deterministic, memory-safe execution. Contemporary backends embed both static and dynamic policy enforcement, restricting file I/O, network, and environment variables while maintaining extensive logging.
Cloud-Based Execution Platforms
Production deployments operate on 25,000 CPU-core clusters organized into specialized pod configurations — separating judging pods from execution pods with exclusive core assignment. Two-tier designs use 8,500 execution pods at concurrency 1 plus 2,000 judging pods. Runtimes support C, C++, Java, Python, Rust, Go, C#, PHP; engines like JUDGE0 cover 60+ languages in sandboxed Docker.
6.2 Interactive Development Interface Environment
AI-Native Development Interfaces
Two paradigms dominate: inline suggestion (next-token prediction within the editor) and conversational interaction. Integrating both yields higher task efficiency and user satisfaction. Cursor and Q Developer integrate contextual memory and multi-turn reasoning, maintaining persistent dialogue histories.
Remote Development & Standards
GitHub Codespaces and DevContainer provide reproducible workspaces accessible via browsers or local editors. Standardization efforts include Model Context Protocol (MCP) for context exchange, Language Server Protocol (LSP) for diagnostics/completion/navigation, and Debug Adapter Protocol (DAP) for debugging. Together these allow coding agents to function as first-class participants in conventional ecosystems.
6.3 Distributed Orchestration Platform Environment
CI/CD Pipeline Integration
CI/CD ensures automatically generated code passes rigorous validation before integration. Pipeline-as-Code practices enable reproducibility through versioned artifacts. In Vibe Coding, CI/CD extends with agent participation — agents generate code, perform static analysis, and self-test, while human oversight remains indispensable for critical verification.
Cloud Compute Orchestration & Multi-Agent Frameworks
Distributed platforms employ frameworks that dynamically provision resources. TOSCA provides platform-agnostic interoperable models for cloud applications as typed directed topology graphs. Multi-agent frameworks AutoGen, CrewAI, MetaGPT, and LangGraph coordinate specialized agents through structured communication channels. LangGraph in particular formalizes collaboration as a graph of nodes and edges, enabling systematic reasoning over dependencies and task flows. Challenges remain around communication efficiency, synchronization, and conflict resolution.
7 · Feedback Mechanisms #
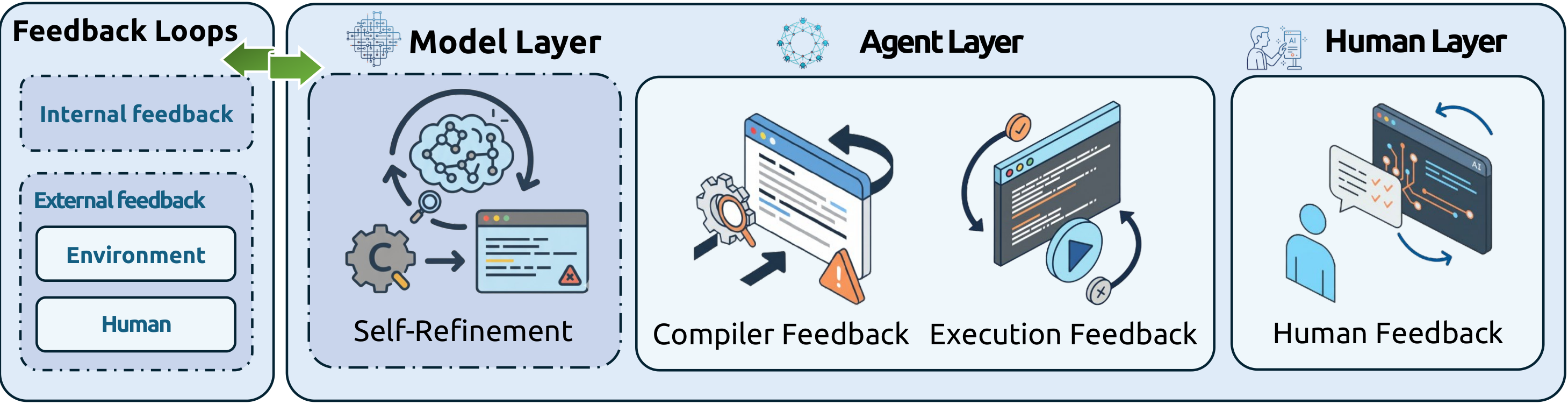
7.1 Compiler Feedback
Compiler feedback spans coarse-grained (binary success / failure) and fine-grained (detailed errors and locations) signals. Modern architectures integrate compiler feedback through multi-agent systems (Code Teachers, Review Agents) and RL approaches (RLCF, PPOCoder, COMPCODER). Static analysis employs tools like pylint and Black, complexity tools (OClint), formal verification (Frama-C, nuXmv), and vulnerability detection (Slither). Runtime feedback loops include CompCoder (44.18% → 89.18% compilation success), CodeRL, RLCF, INTERVENOR, CoCoGen, Cycle, LDB, and ReflectionCoder.
Limitations: coarse error messages, project-specific context not fitting in prompts, inconsistent workflows. Effectiveness depends heavily on context — surfacing errors without resolution context shows limited improvement.
7.2 Execution Feedback
Unit Test Execution Results
Unit tests provide pass/fail signals and detailed failures. TDD has proven merit. PyTest, unittest, JUnit are primary frameworks. Applications span RL approaches, search-based debugging (BESTER), filtering (CodeT achieves 65.8% pass@1 on HumanEval), and test-time scaling.
Challenges: unreliability of AI-generated unit tests (circular dependency problems), scalability of running thousands of samples, and limited test coverage missing edge cases.
Integration Test Feedback & Runtime Error Handling
OpenHands pioneered end-to-end agent test frameworks combining traditional integration testing with foundation-model mocking. Structured feedback formats achieve superior results, with diminishing returns after 2–3 iterations. Runtime error taxonomies identify 5 primary types (syntax, parameter/attribute, output type, logical, timeout/runtime) and 36 exception types across 12 agent artifacts. PyCapsule pairs programmer / debugging / executor agents with error handlers; Healer with GPT-4 handles 88.1% of AttributeErrors.
7.3 Human Feedback
Interactive Requirement Clarification
State-of-the-art Code LLMs generate code outputs in over 63% of ambiguous scenarios without seeking necessary clarifications; 72% of software defects in production environments originate from misunderstood requirements. ClarifyGPT pioneered consistency-checking between multiple generated solutions; ClarifyCoder uses synthetic data and instruction tuning. Interactive clarification yields +45.97% absolute pass@1 within 5 interactions.
Code Review Feedback (RLHF, DPO, alternatives)
RLHF aligns models via human-preference reward modeling and policy optimization. DPO simplifies via direct classification-style loss. PRO extends pairwise preferences to rankings. NLHF poses preference learning as a two-input Nash problem. Diffusion-DPO ports DPO to text-to-image. To reduce annotation cost, RLAIF uses LLM-generated feedback and AutoPM elicits pairwise comparisons under helpfulness, honesty, harmlessness criteria.
7.4 Self-Refinement Feedback
Self-Evaluation and Critique
Self-Refine enables structured generate → critique → refine cycles requiring no additional training. Variants: RCI, CRITIC, Self-Correct. Code's executable nature provides immediate objective feedback — Self-Debugging, Self-Edit, CodeChain, LeTI, OpenCodeInterpreter unify generation / execution / refinement. Critical caveat: self-correction works primarily when reliable external feedback is available; large-scale fine-tuning appears necessary for effective self-correction. GPT-4 gains +8.7 pts in code optimization and +13.9 pts in readability via Self-Refine.
Multi-Agent Collaborative Feedback & Reflection
Inter-agent feedback (peer reflection, shared observations, plan evaluation) complements self-feedback. Hybrid value functions combine quantitative and qualitative assessment (SWE-Search). Frameworks like CodeCoR introduce reflection agents between generation / testing / repair. Reflexion uses verbal reinforcement with Actor / Evaluator / Self-Reflection modules and dual-memory architecture, achieving 91% pass@1 on HumanEval (+11 pts vs. GPT-4 80%). Self-Refine consistently yields ~20% absolute improvement across applications with minimal compute overhead.
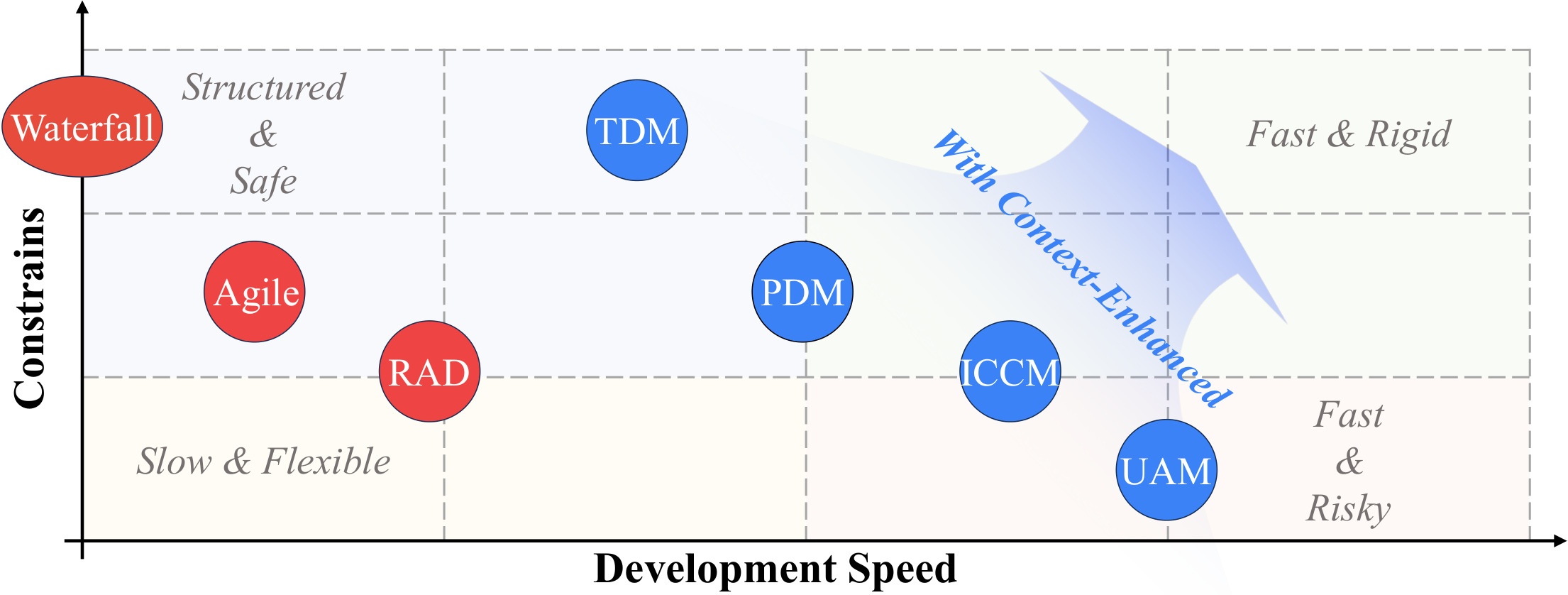
8 · Vibe Coding Development Models #
8.1 Framework Principles
We propose a three-dimensional classification framework categorising Vibe Coding paradigms by: (1) human quality-control level; (2) structured constraint mechanisms; (3) context-management capability. Combinations yield five core models — UAM, ICCM, PDM, TDM, CEM — where the first four are distinct workflows and CEM is a horizontal enhancement combinable with any other model.
The models are not mutually exclusive but composable development strategies. The essential distinction across all models lies in the boundary of human–AI collaboration: in UAM, AI dominates while humans merely provide requirements; in ICCM, humans review while AI executes; in PDM, humans design while AI implements; in TDM, machines verify while humans define standards.
| Model | Upfront Investment |
Human Control |
Structured Constraints |
Dev Speed |
Code Quality |
Maintain- ability |
Security | Tech-Debt Risk |
SE Counterpart |
|---|---|---|---|---|---|---|---|---|---|
| UAM | None | None | None | Strict | Low | Low | Low | High | RAD |
| ICCM | Low | Strict | Moderate | High | High | High | Moderate | Low | Pair Programming |
| PDM | High | Strict | Strict | Moderate | High | Strict | High | Low | Waterfall |
| TDM | High | Moderate | Strict | Moderate | Strict | High | Strict | None | TDD |
| CEM | Moderate | — | — | +1 lvl | +1 lvl | +1 lvl | +1 lvl | −1 lvl | — |
8.2 Unconstrained Automation Model (UAM)
UAM most closely aligns with the original Vibe Coding definition: complete trust in AI output, minimal code scrutiny, correctness validated through functionality testing rather than code comprehension. It emphasizes high development velocity and low technical barriers, enabling non-programmers to rapidly construct prototypes — sometimes dozens of times faster than traditional approaches. It is conceptually similar to Rapid Application Development (RAD).
The absence of human code review allows AI-generated code to potentially harbor security vulnerabilities, accumulate technical debt, and produce code that is difficult to maintain. UAM is suitable only for low-risk scenarios such as disposable prototypes, proof-of-concepts, and personal utilities; it is not recommended for production systems, safety-critical applications, or codebases requiring long-term maintenance.
8.3 Iterative Conversational Collaboration Model (ICCM)
ICCM positions AI as a programming partner rather than a fully autonomous agent. Developers review and comprehend each AI output before deciding whether to accept it: AI generates → human reviews and understands → testing validates → acceptance decision. The model parallels pair programming in agile development, with AI as Driver and the human as Navigator.
ICCM maintains high velocity while ensuring code quality, significantly reducing technical-debt accumulation and security vulnerabilities versus UAM. Drawback: high cognitive load and dependence on developer experience — novices may erroneously trust AI output. Appropriate for professional development environments, medium-to-large projects, and team-collaboration scenarios.
8.4 Planning-Driven Model (PDM)
PDM establishes clear development plans and design specifications before AI coding commences, applying the “architecture-first” philosophy to Vibe Coding. Developers produce a three-document system — technical specification, coding rule file, implementation plan — that serves as the “blueprint” for AI coding. It conceptually aligns with the waterfall model, but retains greater flexibility because AI can iterate rapidly within the architectural framework.
Core value: ensuring directional correctness through upfront planning, avoiding drift and repetitive trial-and-error. A crucial implementation strategy is adopting vertical slice architecture — organising code by business functionality rather than technical layers, with each feature implemented end-to-end from database to UI.
8.5 Test-Driven Model (TDM)
TDM applies TDD's philosophy: first define tests and acceptance criteria, have AI generate code satisfying the tests, ensure quality through automated testing rather than manual review. Tests serve as precise constraints — objective success criteria. Following the classic red-green-refactor cycle, humans write test cases and AI writes implementation code.
Advantage: replacing human judgment with machine verification. When test coverage is comprehensive, passing tests can be confidently assumed to meet behavioural requirements. When tests fail, failure messages precisely pinpoint issues. Typically integrates with automation tools — pre-commit hooks, formatting, type checking — enforcing quality gates. Particularly suitable for core algorithm implementation, production-grade applications, critical business logic, and codebases requiring long-term maintenance.
8.6 Context-Enhanced Model (CEM)
CEM is not an independent workflow but a horizontal enhancement capability layered onto any other model — enabling AI to thoroughly understand existing codebases, technology stacks, and coding conventions through retrieval-augmented generation, codebase vector indexing, documentation loading, and rule constraints. When users submit requirements, the system automatically retrieves relevant code snippets, documentation, and rules.
CEM significantly improves accuracy and consistency, particularly for large codebase maintenance, cross-file refactoring, and global operations. Compositions: UAM + CEM = controlled rapid prototyping; ICCM + CEM = large-codebase maintenance; PDM + CEM = generated code conforming to project specifications; TDM + CEM = superior code quality. Typical implementation uses automatic-retrieval or manual-reference strategies, with tools creating vector indices during project initialization.
9 · Future Impact and Open Challenges #
9.1 Reengineering the Development Process
Traditional SDLC models, from Waterfall to Scrum, were designed around human-authored code and predictable progression through discrete phases. Vibe Coding introduces AI-mediated development cycles operating at compressed timescales — from the weeks typical of Agile sprints to seconds or minutes.
From Phased Lifecycles to Continuous Micro-Iterations
The traditional edit-compile-debug loop is complemented by a prompt-generate-validate cycle organised around iterative goal-satisfaction cycles. Each exchange generates a testable artifact, blurring SDLC phase boundaries:
- Requirements & Design. Exploratory Vibe Coding lets a high-level user story translate into prompts, with design emerging from iterative dialogue.
- Implementation. Agents handle syntactic construction while developers focus on higher-level orchestration as system director and prompt engineer.
- Testing & Validation. The “vibe check” is informal acceptance testing; the rigor of formal QA is recovered by integrating the Test-Driven Model.
Redefinition of Developer Roles and Skill Sets
Beyond traditional code production, developers must develop: intent articulation and prompt engineering; system-level / behavioral debugging; context curation and management; and architectural oversight. Code reviews expand beyond line-level correctness to validation of prompt history, generated tests, and observed behavior. “Pair programming” may evolve into “mob prompting”, where multiple developers collaborate on crafting prompts and context for a shared AI agent.
9.2 Code Reliability and Security
The core trade-off of Vibe Coding is speed versus certainty. Because LLMs are trained on vast public-code corpora that include buggy and insecure examples, models may reproduce vulnerabilities in novel contexts. Vibe Coding therefore must be augmented by automated guardrails that operate continuously and intelligently within the development loop.
Integrated Security Feedback Loop
- Pre-generation contextual analysis — detect security-sensitive keywords in the prompt and inject secure-coding guidelines or templates.
- In-flight SAST scanning — analyse streaming generated code with AI-enhanced SAST tools and feed vulnerabilities back to the LLM in a closed loop.
- Sandboxed dynamic analysis — execute generated code in an instrumented sandbox for just-in-time DAST, monitoring memory leaks, uncaught exceptions, and insecure communications; automated fuzzing on new API endpoints.
- AI-driven threat modeling — maintain a dynamic threat model so each new feature is analysed in the context of the entire system.
The human remains the final arbiter, but the goal is to transform security from a separate delayed phase into an intrinsic property of code generation itself.
9.3 Scalable Oversight of Vibe Coding Agents
As coding agents evolve toward autonomous generation and deployment, oversight must expand from localized code verification to system-level governance. Recent empirical analyses show that autonomous agents in production pipelines correlate with a tenfold increase in security warnings and technical-debt accumulation within six months of adoption.
Emerging Risks
- Cascading Errors. A single agent’s erroneous completion can trigger downstream faults as subsequent agents consume and redeploy its outputs.
- Dependency Proliferation. Nearly one-fifth of packages suggested by code generation models are nonexistent or untrusted, creating dependency-confusion attack surface and inflating SBOM/supply-chain risk.
- Alignment Failures. Agentic systems interpret underspecified objectives probabilistically, optimising for textual success rather than normative correctness.
Toward Scalable Oversight Architectures
A central idea in alignment research is enabling weak-to-strong generalization: using relatively weak supervisors (humans or smaller models) to robustly guide much more powerful coding agents. Approaches include:
- Hierarchical weak-to-strong supervision. Decomposing complex judgments into simpler subtasks manageable by weaker supervisors. OpenAI’s superalignment experiments showed that GPT-4 fine-tuned under GPT-2-level guidance with confidence-based losses can recover GPT-3.5-level performance on complex reasoning.
- Multi-agent debate and critique. Two LLMs alternately produce and test code while generating adversarial unit tests against each other (DebateCoder), fusing automated testing and AI critique into a self-correcting oversight loop.
- Continuous monitoring and automated safeguards. Model-integrated static analyzers and runtime scanners; RL-based watchdog agents that detect deviations from specifications.
Theory indicates oversight success rates decline sharply when an agent's capability surpasses its overseer by several hundred Elo points — underscoring the need for continuous co-evolution between overseers and agents.
9.4 Human Factors in Vibe Coding
Mental-Model Shift: From Code Logic to Context Engineering
Developers increasingly act as context engineers: curating and structuring prompts, providing background, defining constraints. The empirically observed workflow is “specify–verify–revise”, where prompting substitutes for manual implementation and verification becomes the central locus of human activity.
Evolving Developer Skill Sets
- Prompting and context design — modular prompt construction, retrieval-augmented prompting, prompt libraries as formal engineering artifacts.
- Task decomposition — explicitly defined subtasks, shifting from manual implementation to steering AI behavior.
- Quality supervision and verification — automated testing, static analysis, formal verification as mechanisms of oversight.
- Agent governance and security — access control, execution privileges, provenance tracking under least-privilege principles.
Team Collaboration, Accountability, and Education
AI tools increasingly assume roles traditionally associated with junior developers (boilerplate, documentation, test cases), reshaping collaboration patterns. Effective trust calibration — neither blind acceptance nor excessive skepticism — is critical. Computing curricula should integrate training in prompting, AI governance, and human-AI collaboration; at the organisational level, product design, requirements engineering, and test creation may gain importance while low-level code implementation becomes increasingly automated.
10 · Conclusion #
This paper advances Vibe Coding from scattered practice to a principled, research-grounded discipline. We formalize Vibe Coding as a triadic system that couples human intent and quality control (“what / why”), project context (“where”), and coding agents’ decision policies (“how”), providing a first Constrained MDP formulation that specifies roles, interfaces, and optimization targets for agentic software development.
Building on this foundation, we consolidate the field into five development models — Unconstrained Automation, Iterative Conversational Collaboration, Planning-Driven, Test-Driven, and Context-Enhanced — that practitioners can compose to meet distinct risk, speed, and governance requirements. Our triadic formulation positions Vibe Coding as an instance of human–cyber–physical systems, reflecting the convergence of human intelligence, autonomous computation, and physical software artifacts in modern development.
The work systematizes the technical substrate: model training and post-training for code; agent capabilities in planning, memory, and tool-mediated action; execution infrastructure; and feedback channels spanning compiler, runtime, human oversight, and self-refinement. By organising these components, we clarify how context management and executable feedback loops — rather than model quality alone — determine performance and maintainability in long-horizon software tasks.
Our contributions: (i) a formal definition of Vibe Coding as a constrained decision process over the human–project–agent triad; (ii) a unified taxonomy of five development models integrating existing practices; (iii) a comprehensive synthesis of the ecosystem spanning LLMs for code, agent capabilities, development infrastructure, and multi-source feedback; and (iv) an articulation of the central role of context engineering and the key challenges across technical infrastructure, security mechanisms, and human factors.
Cite this work #
@misc{ge2025survey,
title = {A Survey of Vibe Coding with Large Language Models},
author = {Yuyao Ge and Lingrui Mei and Zenghao Duan and Tianhao Li and Yujia Zheng and
Yiwei Wang and Lexin Wang and Jiayu Yao and Tianyu Liu and Yujun Cai and
Baolong Bi and Fangda Guo and Jiafeng Guo and Shenghua Liu and Xueqi Cheng},
year = {2025},
eprint = {2510.12399},
archivePrefix = {arXiv},
primaryClass = {cs.AI},
url = {https://arxiv.org/abs/2510.12399}
}