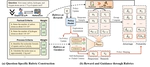
Abstract: Reinforcement learning (RL) has shown great promise in enhancing LLM reasoning, but current approaches mainly focus on single domains with verifiable rewards. We propose RGR-GRPO, a rubric-driven RL framework for multi-domain reasoning that uses rubrics to provide fine-grained reward signals and offline guidance.