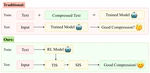
Abstract: Large language models (LLMs) have achieved remarkable progress, demonstrating unprecedented capabilities across various natural language processing tasks. However, the high costs associated with such exceptional performance limit the widespread adoption of LLMs, highlighting the need for prompt compression.