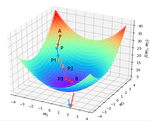
Abstract: Prompt-based adversarial attacks have become an effective means to assess the robustness of large language models (LLMs). However, existing approaches often treat prompts as monolithic text, overlooking their structural heterogeneity-different prompt components contribute unequally to adversarial robustness.