Abstract
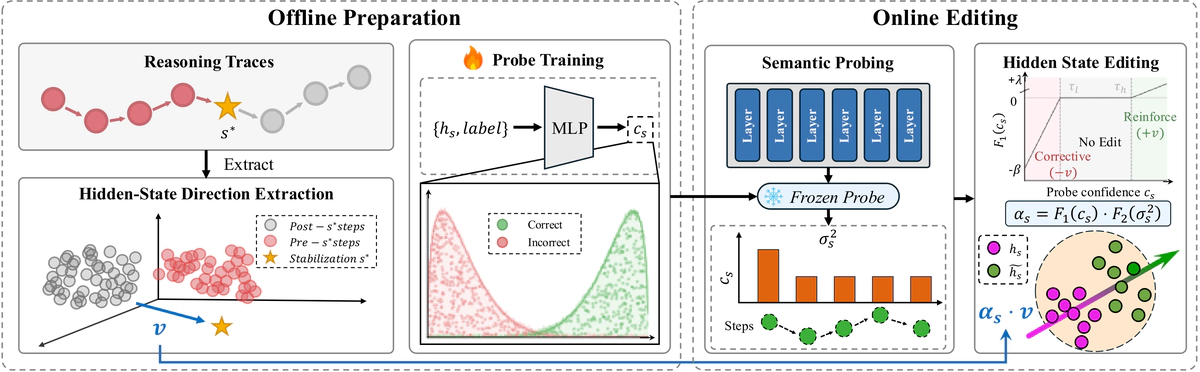
Large reasoning models (LRMs) generate extended chains of thought, but do they internally know when they have already found the correct answer? We investigate this question by probing hidden states during reasoning. A lightweight probe on hidden states identifies per-step reasoning correctness with high accuracy and shows a sharp jump at the moment of answer stabilization, providing strong affirmative evidence. This information is substantially more accessible through hidden states than through token-level signals: in controlled equal-dimension comparisons using the same classifier, hidden-state probes markedly outperform token-level probes. We propose SHEAR (Semantic Hidden-layer Editing with Anchored Reasoning), which directly exploits this hidden knowledge through a semantic confidence probe and a stability-anchored editing direction that jointly determine when and how to intervene. SHEAR achieves the highest or tied-highest results on six mathematical reasoning benchmarks across three LRM scales, with statistically significant improvements against the strongest baseline in most configurations. Reversing the editing direction causes catastrophic collapse, indicating that it operates on genuine reasoning structure. Our findings indicate that reasoning quality is far more accessible through hidden states than previously recognized, and it can be exploited during generation.