Modality-Grounded Contrastive Decoding for Cross-Modal Hallucination Mitigation
Abstract
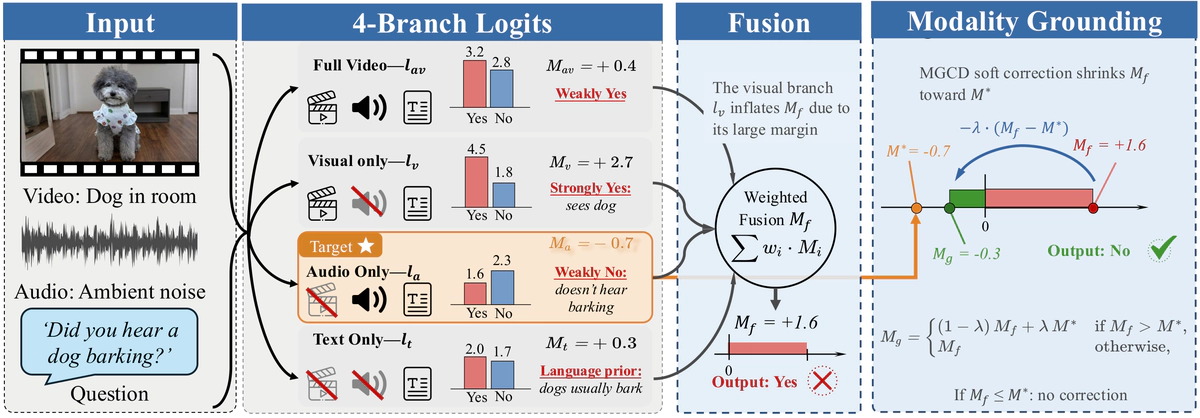
Multimodal large language models suffer from cross-modal hallucinations, where signals from one modality bias predictions about another. To quantify this, we decompose fused logits into per-modality contributions and define Cross-Modal Interference (CMI) ratio, which measures the relative dominance of the non-target modality in the fused prediction margin. CMI provides a per-sample diagnostic of cross-modal interference: high-CMI samples exhibit error rates 19–40 percentage points higher than low-CMI samples. Further analysis shows that the target modality’s independent judgment carries critical corrective information, but exploiting it effectively requires continuous soft correction rather than hard override, which degrades accuracy by up to 9.6%. We propose Modality-Grounded Contrastive Decoding (MGCD), a training-free framework that softly anchors the fused prediction toward the target modality’s own judgment when the former overshoots, while preserving the original prediction otherwise. MGCD introduces only a single hyperparameter with a wide effective range, and the optimal value transfers across datasets with positive gains, requiring minimal per-task tuning. The method proves effective across both end-to-end and modular architectures, and systematic comparison against five alternative grounding strategies confirms that anchoring to the target modality continuously is the only configuration that improves over the ungrounded baseline. Across architecturally diverse models and multiple benchmarks, MGCD recovers 52–70% of the oracle ceiling on fixable errors and consistently improves over all baselines on aggregate metrics, with gains of up to 11.4% over standard decoding. Our results highlight that the correction strategy is as important as the choice of corrective signal, which existing inference-time methods do not address.