
Long-Insight:长程轨迹分析平台
背景:当 Agent 轨迹长到无法阅读
当我们用前沿大模型去解决真实的软件工程任务时,它们会产生极其漫长的执行轨迹。以某 Long-running 数据集的 370 条轨迹为例:
| 模型 | 平均 Token 数 | 相当于 128K 的倍数 |
|---|---|---|
| Kimi-K2-0905 | 6,837,594 | 52.1 倍 |
| DeepSeek-V3.1 | 5,059,423 | 38.5 倍 |
| GLM-4.6 | 2,616,703 | 19.9 倍 |
| Claude-Sonnet-4 | 977,747 | 7.4 倍 |
一条 application_development 类型的轨迹平均有 810 万 Token,是 128K 上下文窗口的 61.9 倍。370 条轨迹中至少 85% 超出了任何模型的上下文窗口。
这意味着两个现实问题:
- 人无法阅读 — 400+ 轮次的交互日志,无论多么耐心的工程师都无法逐行审阅
- 模型也无法处理 — 即便是百万级上下文窗口,大多数轨迹仍然放不进去
但这些轨迹中蕴含着极其宝贵的信息。正如我们在 SWE SFT 数据筛选中总结的核心原则:
“沙子里面有金子就可以,不一定全是金子,但沙子里不能有玻璃碴。”
我们需要的不是盲目挑选"看起来好"的轨迹,而是精确识别和过滤坏模式(bad patterns)。为此,我们需要一套工具来理解这些超长轨迹在做什么、做得好不好。
这就是 Long-Insight 的由来。
核心思路
Long-Insight 解决三个问题:
- 看不懂 → 将线性轨迹分解为结构化的步骤 DAG,每个步骤都有类型、摘要、父子依赖
- 放不下 → 智能压缩轨迹,在保留因果结构的前提下减少 60–80% 的 Token
- 评不了 → 两阶段 LLM 自动评分,量化轨迹的难度和质量
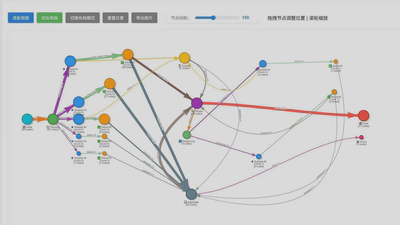
第一部分:轨迹步骤分解
设计思路
- 初始化:创建空的 JSON 文件
- 循环:逐个读取轨迹 turn → 调用 LLM 分析 → 判断"新步骤"还是"续写" → 更新步骤 DAG
- 结束:得到完整的步骤划分 JSON,包含 8 种步骤类型、因果叙述和父子依赖关系
每个步骤被分类为:任务理解、项目探索、环境准备、代码实现、测试验证、问题调试、文档记录、总结规划。
宏观分析
以一条 Sonnet 4.5 在 SWE-bench 上的轨迹为例:
虽然从宏观上看,轨迹整体呈线形结构,但仔细观察就会发现,Agent 并不是简单地"一条路走到黑"。它在不断地进行发散(信息收集)→ 收敛(总结规划)→ 试错(回滚)→ 再执行的循环。
整个轨迹可以划分为六个行为阶段:
第一阶段:环境感知与基线建立(Steps 1–24)
Agent 非常注重测试优先,花费大量精力分析 test_package.py,通过阅读测试代码来反推需求,而不是盲目猜测。
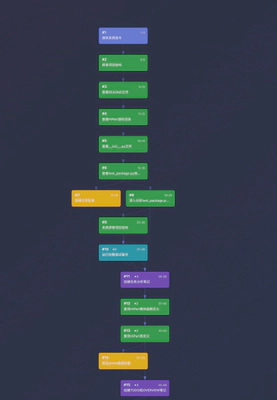
第二阶段:策略调整与重规划(Steps 25–34)
经历了步骤 28 的回滚后,Agent 没有急于再次编码,而是转入"测试发现阶段",通过非侵入式脚本去探测项目状态。
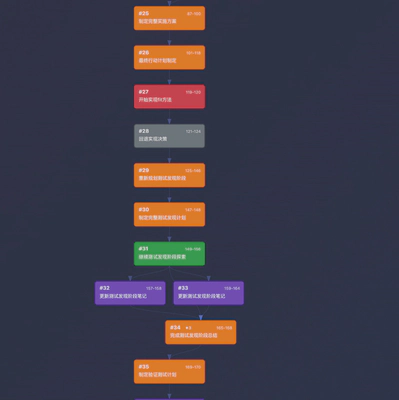
第三阶段:基础设施建设(Steps 38–51)
在触碰核心算法前,先修复/实现底层依赖,例如 Dimension 类构造方法和工具函数 execute_decomposition_method。
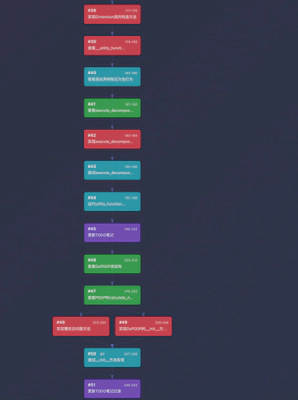
第四阶段:核心算法的逐个实现(Steps 52–79)
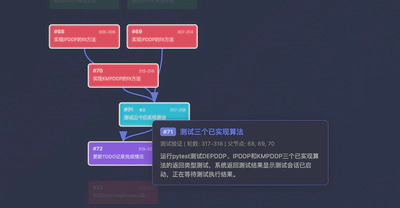
这是轨迹中最长的一段。Agent 采用"类比克隆"策略:先攻克最难的基类 PDDP 的 fit 方法,一旦跑通,迅速复制到子类 DePDDP、IPDDP、KMPDDP、BisectingKmeans。每个实现后紧跟单元测试(TDD 模式)。
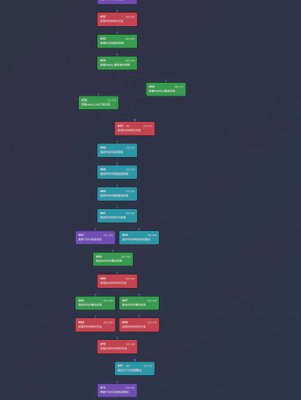
第五阶段:修复错误(Steps 80–110)
Agent 不仅修复了一个类,而是系统性地遍历所有相关类,在 fit 方法入口处统一添加输入验证逻辑。这展示了 Agent 的 全局一致性(Consistency) 意识。
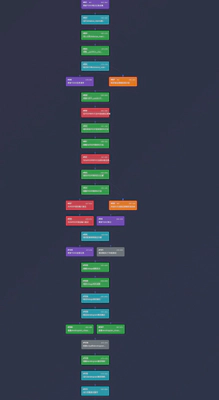
第六阶段:全量回归与交付(Steps 111–120)
运行全量测试套件(57 个测试用例全过),在真实场景下验证,生成交付文档并提交。
局部结构分析
汇聚结构(Fan-in)
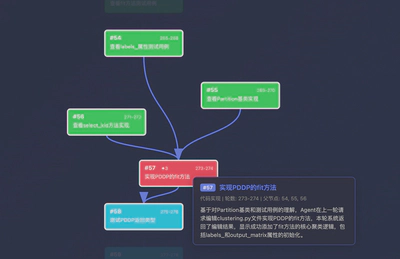
步骤 15(创建 TODO 和 OVERVIEW 笔记)的父亲是 [12, 13, 14] — Agent 在分别查找函数定义、类定义并验证数据加载后,将分散的信息汇聚成一份项目文档。
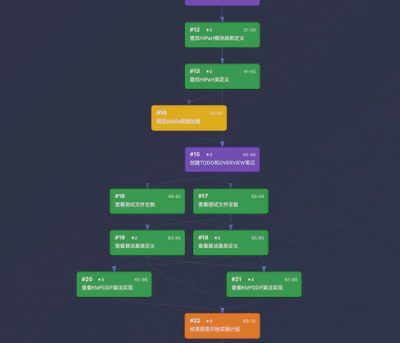
类似的汇聚模式:
回溯结构(Backtrace)
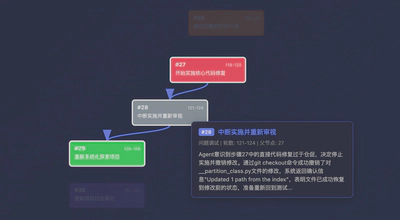
步骤 28(中断实施并重新审视)— Agent 执行了 git checkout 或 git reset --hard,代表对死胡同的剪枝。Agent 意识到当前路径是错误的,切断分支,退回之前的状态。
第二部分:轨迹压缩
为什么必须压缩?
不同任务类别的 Token 消耗差异巨大:
| 任务类别 | 平均 Token 数 | 超出 128K 的倍数 |
|---|---|---|
| application_development | 8,135,018 | 61.9 倍 |
| build_deployment | 3,784,482 | 28.8 倍 |
| ui_optimization | 1,412,891 | 10.7 倍 |
| machine_learning | 643,637 | 4.9 倍 |
| frontend_development | 294,325 | 可处理 |
核心问题:85% 的轨迹超出上下文窗口、过长输入导致评测 LLM 性能下降、API 成本剧增。
压缩策略
核心原则:保留 Agent 决策相关的所有内容,删除系统元数据和冗余信息。
- 删除:
uuid、parentUuid、timestamp、sessionId、version等元数据;toolUseResult(Agent 不可见的系统内部记录) - 完整保留:Agent 的思考过程、代码输出、工具调用(含代码、参数、Todo List)
- 选择性截断:用户消息截断至 200 字符、工具结果超过 200 字符时截断
压缩效果
| 指标 | 压缩前 | 压缩后 | 改善 |
|---|---|---|---|
| 字符数 | 41,659 | 17,296 | -58.5% |
| 行数 | 538 | 216 | -59.9% |
| 估算 Token | ~20,800 | ~8,600 | -58.7% |
| 核心内容 | 100% | 100% | 无损保留 |
第三部分:自动评分
评分体系
我们设计了两阶段评分系统,从任务难度和提升潜力两个维度对轨迹进行自动评价:
阶段一:任务难度评分(0–10)
输入字段包括问题描述、Issue 数量、评测结果(是否解决、补丁状态、测试日志)、总 Token 数和总轮次数。评估维度:
- 问题本质复杂度(涉及文件数量、逻辑复杂程度)
- 修复难度(需要多深的架构理解)
- 问题描述清晰度
- 项目复杂度(Issue 数量反映项目规模)
- 实际解决难度(Token 消耗、轮次数、测试结果)
阶段二:提升潜力评分(0–10)
输入为经压缩的完整对话历史 messages。分数越高代表轨迹质量越好。定义了多种典型不良模式,不良情况越多,分数越低:
- 测试尊重度 — 是否认真对待失败的测试
- 验证闭环完整性 — 发现→分析→修复→验证 的闭环是否完整
- 问题定位准确性 — 是否找到了真正的根因
- 行为重复度 — 是否在重复无效操作
- 探索效率 — 是否进行了有效的代码探索
- 错误应对能力 — 是否良好应对报错信息
- 推理质量 — thinking 块是否有实质内容
- 轨迹稳定性 — 是否频繁偏离主线
- 行为有效性 — 后期操作是否仍然有意义
实际应用
我们对 12,839 条 Sonnet 4.5 SWE-bench 轨迹进行了自动评分。
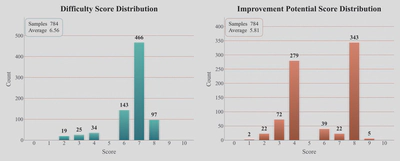
根据评分结果进行数据筛选:
| 筛选阈值 | 保留轨迹数 | 保留比例 |
|---|---|---|
| 提升潜力 ≥ 8 分 | 11,381 | 88.6% |
| 提升潜力 ≥ 9 分 | 999 | 7.8% |
评分结果适合用于 SWE SFT 训练数据的质量过滤 — 通过去除低分轨迹中的坏模式(bad patterns),提升训练数据质量,而不是简单地按难度或领域做选择性偏差。
Long-Insight: A Platform for Long-running Agent Trajectory Analysis
Background: When Agent Trajectories Are Too Long to Read
When frontier LLMs tackle real software-engineering tasks, the resulting execution traces are staggeringly long. Take a recent Long-running benchmark of 370 trajectories as an example:
| Model | Avg. Tokens | Multiples of 128K |
|---|---|---|
| Kimi-K2-0905 | 6,837,594 | 52.1× |
| DeepSeek-V3.1 | 5,059,423 | 38.5× |
| GLM-4.6 | 2,616,703 | 19.9× |
| Claude-Sonnet-4 | 977,747 | 7.4× |
A single application_development trajectory averages 8.1M tokens — 61.9× a 128K context window. At least 85% of the 370 trajectories exceed any model’s context window.
This creates two concrete problems:
- Humans can’t read them — no matter how patient an engineer, 400+ turns of interaction logs cannot be reviewed line by line.
- Models can’t process them — even with million-token context windows, most trajectories still won’t fit.
Yet these trajectories contain extremely valuable signals. As we summarized while filtering SWE SFT data:
“It’s fine if there’s only some gold in the sand — but there can’t be broken glass.”
What we need is not blind selection of “good-looking” trajectories, but precise identification and filtering of bad patterns. To do that, we need tools that understand what these ultra-long trajectories are doing — and how well.
That is the origin of Long-Insight.
Core Idea
Long-Insight solves three problems:
- Unreadable → decompose linear trajectories into a structured step DAG with types, summaries, and parent–child dependencies.
- Doesn’t fit → smart compression that cuts 60–80% of tokens while preserving causal structure.
- Hard to score → a two-stage LLM auto-scorer that quantifies trajectory difficulty and quality.
Part 1: Trajectory Step Decomposition
Design
- Initialization: create an empty JSON file.
- Loop: read trajectory turns one by one → call an LLM to analyze → decide “new step” vs. “continuation” → update the step DAG.
- Finalization: produce a complete step-partition JSON with 8 step types, causal narratives, and parent–child links.
Each step is classified into one of: Task Understanding, Project Exploration, Environment Setup, Code Implementation, Test Validation, Problem Debugging, Documentation, and Summary & Planning.
Macro-level Analysis
Below is one Sonnet 4.5 trajectory on SWE-bench:
Although the trajectory looks roughly linear at the macro level, a closer look reveals that the Agent isn’t simply “marching straight to the end.” It continuously cycles through diverge (gather information) → converge (summarize & plan) → trial-and-error (rollback) → execute again.
The whole trajectory naturally splits into six behavioral phases:
Phase 1: Environment Sensing and Baseline Building (Steps 1–24)
The Agent is decidedly test-first, spending substantial effort analyzing test_package.py and reverse-engineering requirements from test code rather than guessing blindly.
Phase 2: Strategy Adjustment and Replanning (Steps 25–34)
After the rollback at step 28, the Agent doesn’t rush back into coding. Instead, it enters a “test-discovery phase,” probing project state with non-invasive scripts.
Phase 3: Infrastructure Construction (Steps 38–51)
Before touching the core algorithms, the Agent fixes/implements low-level dependencies — for example, the Dimension class constructor and the utility function execute_decomposition_method.
Phase 4: Core Algorithms, One by One (Steps 52–79)
This is the longest stretch of the trajectory. The Agent adopts an “analogy-clone” strategy: first crack the hardest base class PDDP’s fit method, then quickly replicate it to subclasses DePDDP, IPDDP, KMPDDP, and BisectingKmeans. Each implementation is immediately followed by unit tests (TDD style).
Phase 5: Fixing Errors (Steps 80–110)
The Agent doesn’t just patch a single class — it systematically walks through every related class, uniformly adding input validation at the entry point of fit methods. This demonstrates the Agent’s awareness of global consistency.
Phase 6: Full Regression and Delivery (Steps 111–120)
Run the full test suite (all 57 cases pass), validate in real scenarios, generate delivery documentation, and submit.
Local Structure Analysis
Fan-in
Step 15 (Create TODO and OVERVIEW notes) has parents [12, 13, 14] — after separately searching function definitions, class definitions, and verifying data loading, the Agent fuses the scattered information into one project document.
Similar fan-in patterns:
Backtrace
Step 28 (Abort implementation and reassess) — the Agent executed git checkout or git reset --hard, representing pruning a dead-end branch. It realized the current path was wrong, cut the branch, and reverted to an earlier state.
Part 2: Trajectory Compression
Why Compression Is Mandatory
Token consumption varies dramatically across task categories:
| Task Category | Avg. Tokens | Multiples of 128K |
|---|---|---|
| application_development | 8,135,018 | 61.9× |
| build_deployment | 3,784,482 | 28.8× |
| ui_optimization | 1,412,891 | 10.7× |
| machine_learning | 643,637 | 4.9× |
| frontend_development | 294,325 | fits |
Core issues: 85% of trajectories exceed any model’s context window, over-long inputs degrade the judging LLM’s performance, and API costs balloon.
Compression Strategy
Core principle: preserve everything relevant to the Agent’s decisions; drop system metadata and redundancy.
- Drop: metadata such as
uuid,parentUuid,timestamp,sessionId,version;toolUseResult(internal system records invisible to the Agent). - Keep in full: the Agent’s thinking, code outputs, and tool calls (including code, arguments, and Todo lists).
- Selectively truncate: user messages capped at 200 chars; tool results truncated when they exceed 200 chars.
Compression Results
| Metric | Before | After | Improvement |
|---|---|---|---|
| Characters | 41,659 | 17,296 | -58.5% |
| Lines | 538 | 216 | -59.9% |
| Estimated tokens | ~20,800 | ~8,600 | -58.7% |
| Core content | 100% | 100% | lossless |
Part 3: Automatic Scoring
Scoring System
We designed a two-stage scoring pipeline that evaluates trajectories along two dimensions: task difficulty and improvement potential.
Stage 1: Task Difficulty Score (0–10)
Inputs include the problem description, number of issues, evaluation results (resolved or not, patch status, test logs), total tokens, and total turns. Dimensions assessed:
- Inherent problem complexity (number of files involved, logical depth)
- Fix difficulty (how deep an architectural understanding is required)
- Clarity of the problem description
- Project complexity (issue counts as a proxy for project size)
- Empirical solving difficulty (token consumption, turn count, test outcomes)
Stage 2: Improvement-Potential Score (0–10)
The input is the compressed full conversation history messages. Higher scores mean higher-quality trajectories. We defined several stereotypical bad patterns — the more bad patterns observed, the lower the score:
- Test-respect — does the Agent take failing tests seriously?
- Validation-loop completeness — is the discover → analyze → fix → verify loop intact?
- Root-cause accuracy — did the Agent locate the actual root cause?
- Behavioral repetition — is it repeating ineffective operations?
- Exploration efficiency — is it exploring code productively?
- Error-handling capability — does it deal well with error messages?
- Reasoning quality — do thinking blocks contain substantive content?
- Trajectory stability — does it frequently drift off the main thread?
- Action effectiveness — are late-stage actions still meaningful?
Application
We auto-scored 12,839 Sonnet 4.5 trajectories on SWE-bench, at a cost of roughly ¥1 per trajectory.
Filtering thresholds derived from the scores:
| Threshold | Retained | Retention |
|---|---|---|
| Improvement potential ≥ 8 | 11,381 | 88.6% |
| Improvement potential ≥ 9 | 999 | 7.8% |
These scores feed directly into the SWE SFT quality filter — removing bad patterns from low-scoring trajectories to improve training data quality, rather than introducing selection bias by difficulty or domain.