更复杂的 Agent 能带来更好的性能吗?
更复杂的SWE-Agent在SWE-pro bench上相比于mini-swe-agent表现更差且出现了实例卡死

TLDR: 更复杂的SWE-Agent在SWE-pro bench上相比于mini-swe-agent表现更差且出现了实例卡死
ps:本文AI率低于20%
首先抛出一个常见的直觉:agent 框架做得越完善,性能应该越强。 尽管直觉上大家都这么认为,但是目前没有人严谨地证明过。为此,我希望在SWE任务上验证这个直觉是否是正确的🤔。
💡思路如下:
在SWE Pro Bench上测试两个复杂度不同的Agent Framework,对比他们各自的得分。
结果却发现简单的Agent框架反而获得了更高的性能🤯。
背景知识
什么是 SWE 任务? SWE(Software Engineering)任务衡量的是 agent 的端到端真实开发能力:给定一个真实代码仓库和一个 GitHub issue,让 agent 自主地读代码、定位问题、跨文件修改、写出 patch(代码补丁),最后由测试判定是否"解决"。SWE-bench Pro 就是针对这一任务的 benchmark。
SWE-agent 与 mini-swe-agent 是两个面向 SWE 场景的 agent 框架:
- SWE-agent 的核心论点是 Agent-Computer Interface(ACI),即为 agent 精心设计一套专用工具:给它配多种自定义工具、每个工具各有接口;执行则交给独立的
SWE-ReX后端,用持久 pexpect 交互式 shell(工作目录、环境变量跨命令保留),且每条命令先过 bashlex 预解析(切分、语法校验、精确抠退出码)。 - mini-swe-agent 是 SWE-agent 的最小实现(整个 agent 类约 100 行 Python):只有 bash 一个"工具",连模型的 tool-calling 接口都不用;用
subprocess.run执行每条命令,每个 action 完全独立。
介绍完背景,那么问题来了:在同模型、同 benchmark 下,相比于mini-SWE-Agent,SWE-Agent这套"更完善"的工程,是否能带来更高的收益呢??
更完善的 SWE-agent 并没有更强
我使用 Claude Sonnet 4.5 分别在两个 Agent Framework 上,对 SWE-bench Pro 的全部 731 题进行全量测试,限制了最大调用次数为 50 次。
结果如下:
| Agent Framework | N | resolved | 通过率 |
|---|---|---|---|
| mini-swe-agent | 731 | 322 | 44.0% |
| SWE-agent | 731 | 302 | 41.3% |
参照:官方对 Sonnet 4.5 的测试结果约为 43.6%1,mini 的 44.0% 与之吻合,说明了我们实验的可信性。
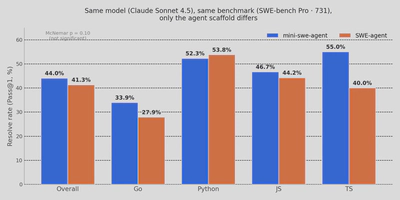
极简的 mini-swe-agent 比 swe-agent 还高了 2.7%。令人意外的是 SWE-agent 全量跑到 722/731 后,最后 9 个实例直接卡死——容器 Up 5–12 小时、日志连续几小时无更新,只能kill掉。而 mini-swe-agent 跑同样这 9 道题却没有此问题。
于我而言,比起结果上的意外,我更好奇为什么这九个实例会卡死🤔。
为什么会有 9 个被卡死的容器
Kill掉容器前,我抓了每个卡死容器的 docker logs,显示:
INFO ... 200 OK POST /run_in_session
🦖 ERROR Bashlex fail: here-document at line 0 delimited by end-of-file (wanted "'EOF'")
容器没死、swerex-remote 进程还在正常返回 200 OK——是 agent 在空转。顺着 agent 的 trace 看,它在用 heredoc 写大文件:
cat > some_file.go <<'EOF'
... 一大段 Go 代码 ...
EOF
根因找到了:SWE-agent 的执行后端 swe-rex,会先用 bashlex(一个纯 Python 写的 bash 解析器)把每条命令解析一遍,再送进容器执行。
麻烦正出在这一步。bashlex 对 heredoc 的支持并不完整,碰到 cat <<'EOF' … 一大段代码 … EOF 这种大块写文件,它会直接解析失败,抛出 Bashlex fail。
解析一旦垮掉,swe-rex 就判断不出这条命令到底有没有跑完、退出码是几;agent 收到一份残缺的反馈,又不会换种写法自救,只能把同一条命令一遍遍重试,容器就这样一卡就是 5 到 12 个小时。
SWE-Agent 为什么要多此一举地先解析命令?
swe-rex 维持着一个长期存活的 shell 会话,让工作目录、环境变量、激活的虚拟环境这些状态能在多条命令之间延续。
但代价是,当命令在一个不断流动的会话里执行时,“它到哪儿算结束、返回码是多少"就不再像跑完一个独立进程那样一目了然,只能靠 bashlex 把命令切开、再注入哨兵字符串去输出流里把退出码捞回来。
好处是:命令既然被解析成了结构,还能做安全检查、命令改写之类更精细的封装,也正是 SWE-agent 主打的 Agent-Computer Interface 思路。它用额外的复杂度,换来了更强的会话语义。
而 mini-swe-agent 则相反,走的是极简路线。它根本不维持会话,每条命令都用一句 subprocess.run(shell=True) 直接丢给系统真正的 shell:
# minisweagent/environments/local.py
result = subprocess.run(
command,
shell=True, # 交给系统 shell(/bin/sh -c)
text=True, cwd=cwd, timeout=timeout,
stdout=subprocess.PIPE, stderr=subprocess.STDOUT,
)
这么做丢掉了会话状态,每条命令都从头开始,agent 得自己把路径和环境写全;但也正因如此,它绕开了所有"自己解析 bash"的麻烦。heredoc 再大也是真 shell 的本职工作,命令跑完、进程一退出,退出码自然就有了。
于是同一条写大文件的命令,在 SWE-agent 撞上 bashlex 的短板、把容器拖死,在 mini-swe-agent 这边却平平无奇地跑了过去。这就是一组很典型的工程取舍——swe-rex 用更高的复杂度换更强的会话语义,也因此多背了一类失败面;mini 放弃了会话的便利,换来更小、更可控的出错空间。
结语
从广义的意义来说,这次的发现证明了奥卡姆剃刀原则:越简单的东西反而是越有效的(也可能是第一性原理)。
当然,我认为这只是一个非常简单的 toy experiment。这并不能说明更复杂、更精密的 agent 效果就不好,可能只是因为 SWE-agent 恰好有这么一个 bug。也许一个经过精细调教的、更复杂的 agent 可以比 mini agent 更好。
当然,anyway,这只是一些猜测。接下来我会用更严谨的实验深挖开头提到的问题,感兴趣的朋友欢迎持续关注。
附录
分语言对比
| 语言 | mini | SWE-agent | 谁优 |
|---|---|---|---|
| go | 95/280 = 34% | 78/280 = 28% | mini +6pp |
| python | 139/266 = 52% | 143/266 = 54% | SWE-agent +2pp |
| js | 77/165 = 47% | 73/165 = 44% | mini +3pp |
| ts | 11/20 = 55% | 8/20 = 40% | mini(N=20,小样本不稳) |
mini 的优势几乎全部来自 Go,高出 6 个百分点、差 17 题,而这里面光 gravitational/teleport 一个仓就占了大头(仅 mini 解出的有 16 道,仅 SWE-agent 解出的只有 5 道)。这其实并不意外:Go 题大多是体量大、改动多的重仓,正好是最容易触发 SWE-agent heredoc 卡死的地方。可一旦换到 Python,SWE-agent 反而还略高了 2 个百分点。
配对显著性
再看配对显著性。把 731 题按 instance_id 一一对齐,能分成四类:
| 数量 | |
|---|---|
| 都过 | 245 |
| 仅 mini 过 | 77 |
| 仅 SWE-agent 过 | 57 |
| 都没过 | 352 |
真正分出胜负的是那 134 道一边过、一边不过的题,其中 mini 占 77、SWE-agent 占 57,确实偏向 mini,但 McNemar 精确检验给出的 p 值是 0.10,谈不上显著。更能说明问题的是另外两类:245 道两边都解得出、352 道两边都解不出,这说明它们能覆盖的题其实高度重叠。
卡死的公平性核算
最后补一笔公平账,对于那 9 个卡死的实例(flipt 5 个、teleport 2 个,加上 vuls 和 tutanota 各 1 个)逐题核对下来,真正算得上"不公平丢分"的其实只有 2 个,也就是 mini 能解、而 SWE-agent 仅仅因为卡死被记了 0 分的 vuls e4728e38 和 teleport 47530e1f。就算把这 2 分补回去,SWE-agent 也不过从 302 升到 304(41.6%),mini 仍是 44.0%,差距反而更小,“不显著"的结论丝毫没变。况且换个角度想,执行后端稳不稳本来就是一个 agent 端到端能力的一部分,在"衡量整套 scaffold"的口径下,记 0 并不算冤枉它😅。
TL;DR. On SWE-bench Pro, the more elaborate SWE-agent underperforms the minimalist mini-swe-agent, and additionally suffers from instances that hang indefinitely.
A widely held intuition holds that the more complete an agent framework is, the better it should perform. Although this assumption is rarely questioned, to my knowledge it has never been rigorously verified. I therefore set out to test it on a software-engineering (SWE) task.
The design is simple: evaluate two agent frameworks of differing complexity on SWE-bench Pro and compare their scores. The result was counterintuitive: the simpler framework achieved the higher score.
Background
What is an SWE task? A software-engineering (SWE) task measures an agent’s end-to-end, real-world development ability: given a real code repository and a GitHub issue, the agent must autonomously read the code, localize the problem, make cross-file edits, and produce a patch, which is then judged “resolved” by a suite of hidden tests. SWE-bench Pro is a benchmark targeting exactly this kind of task.
SWE-agent and mini-swe-agent are two agent frameworks built for the SWE setting:
- SWE-agent is organized around the notion of an Agent-Computer Interface (ACI): a carefully designed set of dedicated tools, each with its own interface. Execution is delegated to a separate
SWE-ReXbackend, which maintains a persistentpexpectinteractive shell (the working directory and environment variables persist across commands) and pre-parses every command withbashlex(splitting, syntax validation, and precise exit-code extraction). - mini-swe-agent is a minimal reimplementation (the agent class is roughly 100 lines of Python): it exposes a single tool, bash, and does not even rely on the model’s tool-calling interface; each command is executed through
subprocess.run, with every action fully independent.
With this background in place, the central question becomes: under the same model and the same benchmark, does SWE-agent’s heavier engineering actually translate into a higher payoff than mini-swe-agent?
The more elaborate SWE-agent is not stronger
Using Claude Sonnet 4.5, I evaluated both frameworks on the full 731-problem SWE-bench Pro public set, capping the call budget at 50 per problem.
The results are as follows:
| Agent framework | N | resolved | resolve rate |
|---|---|---|---|
| mini-swe-agent | 731 | 322 | 44.0% |
| SWE-agent | 731 | 302 | 41.3% |
For reference, the officially reported figure for Sonnet 4.5 is around 43.6%1; mini’s 44.0% aligns closely with it, which lends credibility to the present setup.
The minimalist mini-swe-agent is, in fact, 2.7 percentage points higher than SWE-agent. More surprisingly, after SWE-agent had completed 722 of the 731 instances, its final 9 instances hung outright: the containers stayed up for 5 to 12 hours with no log activity for hours on end, and had to be killed manually (and thus scored 0). Running the very same 9 problems, mini-swe-agent exhibited no such behavior.
For me, beyond the surprise in the numbers, the more intriguing question was why these 9 instances hung in the first place.
Why did 9 containers hang?
Before killing the containers, I captured the docker logs of each one:
INFO ... 200 OK POST /run_in_session
🦖 ERROR Bashlex fail: here-document at line 0 delimited by end-of-file (wanted "'EOF'")
The containers were alive and swerex-remote was still returning 200 OK; in other words, the agent was merely spinning in place. Tracing the agent back, it was writing a large file via a heredoc:
cat > some_file.go <<'EOF'
... a large block of Go code ...
EOF
This pins down the root cause: SWE-agent’s execution backend, swe-rex, first parses every command with bashlex (a pure-Python bash parser) before dispatching it into the container.
That is precisely where things break. bashlex’s support for heredocs is incomplete; confronted with a large block-write such as cat <<'EOF' … a large block of code … EOF, it fails outright and raises Bashlex fail.
Once parsing collapses, swe-rex can no longer determine whether the command finished or what its exit code was. The agent receives a malformed observation, does not recover by attempting a different approach, and simply retries the same command over and over, leaving the container hung for 5 to 12 hours.
Why does SWE-agent bother parsing commands in the first place?
The answer follows from its design goals. swe-rex maintains a long-lived shell session, so that state such as the working directory, environment variables, and any activated virtual environment persists across commands.
The cost, however, is that when commands run inside a continuously flowing session, “where a command ends and what its return code is” is no longer as self-evident as it is when a standalone process exits. swe-rex must therefore rely on bashlex to split commands and inject sentinel strings in order to recover exit codes from the output stream.
The benefit is that, once a command has been parsed into a structured form, the backend can additionally perform safety checks, command rewriting, and other fine-grained wrapping. This is exactly the Agent-Computer Interface philosophy that SWE-agent champions; on its own terms, the design is sound, trading extra complexity for stronger session semantics.
mini-swe-agent takes the opposite, minimalist route. It maintains no session at all; every command is handed directly to the system’s real shell through a single subprocess.run(shell=True):
# minisweagent/environments/local.py
result = subprocess.run(
command,
shell=True, # hand it to the system shell (/bin/sh -c)
text=True, cwd=cwd, timeout=timeout,
stdout=subprocess.PIPE, stderr=subprocess.STDOUT,
)
This sacrifices session state (each command starts afresh, and the agent must spell out paths and environment itself), but for exactly that reason it sidesteps all the trouble of parsing bash in-process. A heredoc, however large, is the real shell’s native job; once the command finishes and the process exits, the exit code is simply there.
As a result, the same large-file-writing command that crashes the container under SWE-agent, by hitting bashlex’s limitation, runs uneventfully under mini-swe-agent. This is a textbook engineering trade-off: swe-rex buys stronger session semantics at the price of an additional failure surface, whereas mini forgoes the convenience of a session in exchange for a smaller and more controllable space of errors.
Conclusion
Broadly speaking, this finding echoes Occam’s razor: when capability is comparable, the simpler solution is often the more effective, and arguably the more robust, one.
That said, this is admittedly a small toy experiment. It does not establish that more complex, more sophisticated agents are necessarily worse; SWE-agent’s shortfall here is, to a large extent, dragged down by one specific bug. A carefully tuned, more elaborate agent could well surpass mini.
These remain, for now, preliminary conjectures. In follow-up work I intend to investigate the opening question more rigorously: whether a more complete agent is genuinely worth it. Stay tuned.
Appendix
Per-language comparison
| Language | mini | SWE-agent | Winner |
|---|---|---|---|
| go | 95/280 = 34% | 78/280 = 28% | mini +6pp |
| python | 139/266 = 52% | 143/266 = 54% | SWE-agent +2pp |
| js | 77/165 = 47% | 73/165 = 44% | mini +3pp |
| ts | 11/20 = 55% | 8/20 = 40% | mini (N=20, small sample) |
mini’s advantage comes almost entirely from Go, where it leads by 6 percentage points (17 problems); within Go, a single repository, gravitational/teleport, accounts for most of it (16 solved only by mini versus 5 only by SWE-agent). This is unsurprising: Go problems tend to involve large, heavily modified repositories, which is precisely where SWE-agent’s heredoc hang is most likely to be triggered. On Python, by contrast, SWE-agent is actually 2 points higher.
Paired significance
Aligning all 731 problems by instance_id yields four categories:
| Count | |
|---|---|
| Both solved | 245 |
| Only mini | 77 |
| Only SWE-agent | 57 |
| Neither | 352 |
What actually separates the two are the 134 problems solved by exactly one side: 77 for mini and 57 for SWE-agent. The tilt favors mini, but McNemar’s exact test yields p = 0.10, which is not significant. More telling are the other two categories: 245 problems solved by both and 352 solved by neither, indicating that the two scaffolds cover a highly overlapping set of problems.
Fairness accounting for the hangs
Finally, a fairness check. Of the 9 hung instances (5 from flipt, 2 from teleport, and one each from vuls and tutanota), only 2 constitute genuinely “unfair” losses, i.e., problems that mini solved but on which SWE-agent was scored 0 purely because it hung: vuls e4728e38 and teleport 47530e1f. Even crediting those 2 back, SWE-agent rises only from 302 to 304 (41.6%), while mini remains at 44.0%; the gap narrows but the “not significant” conclusion is unchanged. Moreover, the robustness of the execution backend is itself part of an agent’s end-to-end capability, so scoring 0 is not unfair under a “whole-scaffold” evaluation.
SWE-bench Pro, https://arxiv.org/abs/2509.16941 ↩︎ ↩︎