llama模型量化报告(二)
llama模型量化报告系列

零. 任务概述
- 深入研究LLM.int8方法、
了解emergent feature现象https://arxiv.org/pdf/2208.07339.pdf在论文《LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale》中int8 absmax和zeropoint具体是什么含义?作者设计这种方法的灵感来自于哪里?对于猜测“outliers”的存在是为了使模型提取特征是否成立?如果成立仅保留outliers会有多少的精度损失?能否设计一种方法保留一定比例的非outliers以平衡性能损失和模型对计算资源的占用?
- llama.cpp背后的算法是什么?https://github.com/ggerganov/llama.cpp
8-BIT OPTIMIZERS VIA BLOCK-WISE QUANTIZATION
Author:Tim Dettmers
提出的一种对 optimizer 进行量化的方法,在不修改超参,不影响模型精度的情况下,把 adam / momentum 的状态量量化至 int8,从而缓解训练时的显存压力。
与项目关系不大
LLM.int8(): 8-bit Matrix Multiplication
for Transformers at Scale
Author:Tim Dettmers
零. Background:
Absmax quantization:
最简单的量化手段,可以实现fp16$\rightarrow$int8。
简单来讲就是将fp16映射至[-127,127]的int8整数。
比方说有一组fp16的向量[-100,0,50,100],经过Absmax量化后,100对应127,50对应63.5,0对应0,-100对应-98.73。
它的问题在于如果向量中出现取值较大的outliers就会导致其他的值在量化后被磨除。
例如,当向量为[-0.10, -0.23, 0.08, -0.38, -0.28, -0.29, -2.11, 0.34, -0.53, -67.0]时,经int8量化和反量化处理后向量变为[ -0.00, -0.00, 0.00, -0.53, -0.53, -0.53, -2.11, 0.53, -0.53, -67.00]可见大部分信息在处理后都丢失了。
Zeropoint quantization:
和Absmax思路类似,区别就是Absmax是非对称的,而这个方法是对称的。
以向量[-100,0,50,100]为例,经过Zeropoint量化后,100对应127,50对应63.5,0对应0,-100对应-127。
两种方法在思路、性能、精度上没有区别且都没有解决outliers的问题。
LLM.int8:
作者首先使用了上述两种方法对模型进行量化,但是发现精度下降严重,于是希望找到一种既可以保证精度又可以减少memery占用的方法。
经过实验作者发现在矩阵 $\textbf{X}_{f16}\in\mathbb{R}^{s\times h}$中存在outliers,这些outliers存在于所有的sequence维度s中但是在feature/hidden维度h中的分布却是有规律的。
基于此现象作者想到将存在outliers的维度分离出来进行fp16乘法,其他的维度进行int8乘法。
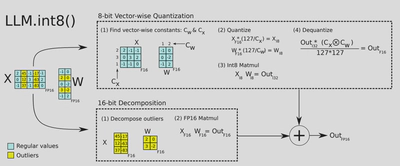
如何定义outliers:
作者设置了一个阈值$\alpha$,超过$\alpha$的值被定义为outliers,而存在outliers的维度需要进行fp16乘法。经过实验,作者发现$\alpha$设置为6及以上可以保证精度不下降。 当$\alpha$被设置为6的时候,有99.9%的维度会进行int8量化,而其余存在outliers的0.1%的维度不会进行量化。对于一个13B的模型,存在outliers的维度不超过7。将矩阵进行拆分的操作会额外占用0.1%的存储空间。
一. Emergent feature
定义:
原文是"Emergence is a gradual change in a property that suddenly undergoes a phase shift and then changes the quality of its substrate.",白话文是“transformer经历了一种逐渐的变化,然后突然发生相移,之后产生了本质的变化”,用中文表达就是“量变引起质变”。在这个过程中,改变的是模型参数量。
发现:
在了解这个过程之前作者介绍了transformer中的两个主线。第一条主线是,神经网络在逐渐提取特征。第二条主线是,神经网络在去除嘈杂的、与上下文无关的特征。用一个例子来解释这个现象:当你想对猫狗进行分类,你可以使用锐化方法,锐化可以突出动物间不同的特征(眼睛,耳朵),也可以去去除相似特征(颜色,潜在的纹理)。transformer也是这个原理。在推理的过程中,transformer会去掉99%无用的信息,仅保留1%有用的信息。
在发生质变之前,各个层使用不同的维度来突出重要特征。但是当质变发生之后,各个层使用相同的六个维度来突出这些特征。
总结来讲就是:
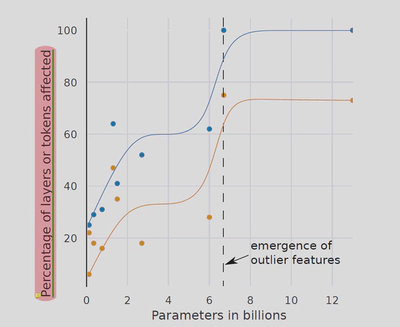
当模型的参数达到6.7B之前,outliers分布在个别层的不同维度中,分布没有规律。
当模型的参数达到6.7B时,outliers的值陡然升高且忽然出现在所有层中,且是仅出现在相同的六个维度。这也解释了为什么以往的量化方法不能应用于大模型:因为自6.7B开始出现了大量的outliers,而以往的量化方法无法很好的处理outliers。
值陡然升高:6B时最大值是15,13B时最大值时60,66B时最大值时95。
忽然出现在所有层中:在6.7B之前不同层使用不同的维度来放大特征。但是6.7B之后,所有的层共同协作来放大特征。
仅出现在相同的六个维度:意味着注意力变得集中。
二. 反思:
- Emergent feature是否只与参数量有关? 并不是,Emergent feature与ppl也有关系。
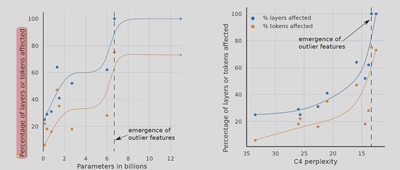
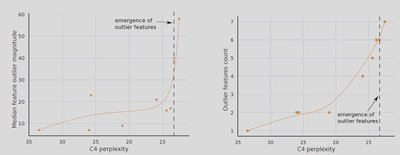
为什么一般的量化方法如int8系列方法中的zeropoint和absmax在大模型中不适用? 因为随着参数量的增加,outliers的数量也在增加,而一般的量化方法遇到outliers就会出现严重的精度损失。
总结一下质变发生时的现象
outliers会出现在所有的层中
outliers规律性的分布在几个维度中
outliers的值陡然上升
outliers的数量也增加
- 能否去除除outliers外的其他维度? 不可以。作者在博客中说到,如果你去除了视觉模型中95%的参数,模型的精度不会受到严重的应先向,但是在NLP的transformer模型中这个数字是30%。而当Emergent发生后,这个数字是5%。