llama模型量化报告(一)
llama模型量化报告系列

零. 任务概述
全部任务:
了解现有的大模型,以及基于llama 的模型量化相关知识
了解量化的相关工具
做量化对比实验:效果,性能
实验评测:效果(人工?自动化?…),性能(速度,没量化前占的显存->量化后)
汇总,下结论
本文完成任务:
了解现有的大模型,以及基于llama 的模型量化相关知识
了解量化的相关工具
一. 现有的大模型技术
目前对大模型的开发的主要方法是Foundation Model+Prompt工程,前者由互联网大厂开源提供,后者由开发者针对不同的业务场景进行定制开发。
目前主流的大模型底座包括由Meta提供的Llama模型等。
其中llama系列提供了四种规格的模型,分别是7B,13B,33B和65B。
本项目使用的底座为llama33B模型。
二. 量化相关知识
Q1.什么是量化?
量化是指将信号的连续取值近似为有限多个离散值的过程。是一种模型压缩手段。
Q2.为什么要量化?
目前服务对显存的占用大,在高并发的环境下可能会导致服务崩溃。因此,需要对模型进行量化节省显存和带宽。
Q3.量化手段有几类?
二值化使用位运算实现并行计算的目的。
对数量化没有看到有在三大平台上实现对数量化的加速库,可能其实现的加速效果不明显。只有一些专用芯片上使用了对数量化。
线性量化线性量化采用均匀分布的聚类中心,原始浮点数据和量化后的定点数据存在一个简单的线性变换关系,是最常用的量化手段。例如,韩松在ICLR2016上获得best paper的论文首次提出了参数量化的手段,即使用聚类算法将相近数值归为一类,复用一个数值达到量化的目的。
但上述三种手段似乎并不能在大模型上使用。
三. 量化手段介绍
1. LLM.int8量化
2022年由来自华盛顿大学的博士Tim Dettmers提出。
论文地址:https://arxiv.org/pdf/2208.07339.pdf
Github链接:https://github.com/timdettmers/bitsandbytes
(1) int8方法介绍
在了解LLM.int8量化之前需要先了解int8量化。 int8量化的主要思想就是将浮点数FP16映射到8位int范围内,即[-127,127]。 设我们有需要量化的向量$\mathbf{x} : [1.2, -0.5, -4.3, 1.2, -3.1, 0.8, 2.4, 5.4]$,首先找到其中最大值 $max(\mathbf{x}) = 5.4$,然后算出量化系数 $\alpha = 127/5.4 = 23.5$。然后将向量中每个元素都与$\alpha$相乘得到量化后的向量$\mathbf{x’} : [28, -12, -101, 28, -73, 19, 56, 127]$。
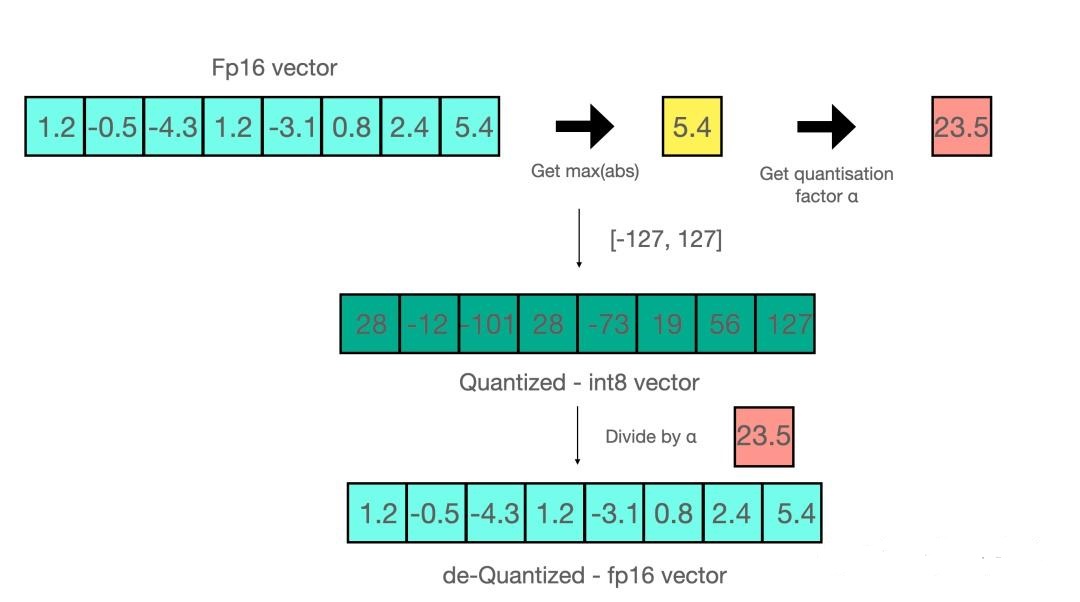
上文介绍了如何对单个int8向量进行量化,但是当向量中出现离群值(Emergent Features) 时int8量化方法就会出现问题。例如,当向量为[-0.10, -0.23, 0.08, -0.38, -0.28, -0.29, -2.11, 0.34, -0.53, -67.0]时,经int8量化和反量化处理后向量变为[ -0.00, -0.00, 0.00, -0.53, -0.53, -0.53, -2.11, 0.53, -0.53, -67.00]可见大部分信息在处理后都丢失了。因此如果直接使用int8对模型量化会导致精度的下降。
(2) LLM.int8 方法介绍
作者通过实验观察到了如下的现象(此处参考知友Strong的文章)提出了混合量化方法 : LLM.int8。
离群值几乎出现在所有的层中,如果我们贸然使用了int8量化手段会导致模型精度严重下降。但是好消息是这些离群值的分布有规律的。如果一个6.7B的transformer模型每个sequence中有150,000个离群值,那么他们只会出现在六个特征维度中(X[:,:,i]中六个不同的i值)。
基于此现象作者提出LLM.int8方法,即**将包含了离群值的几个维度从矩阵中分离出来,对其做高精度的矩阵乘法,其余部分进行量化。**按照作者的描述99.9%的维度都可以使用int8量化,至于0.1%的维度需要进行fp16乘法。
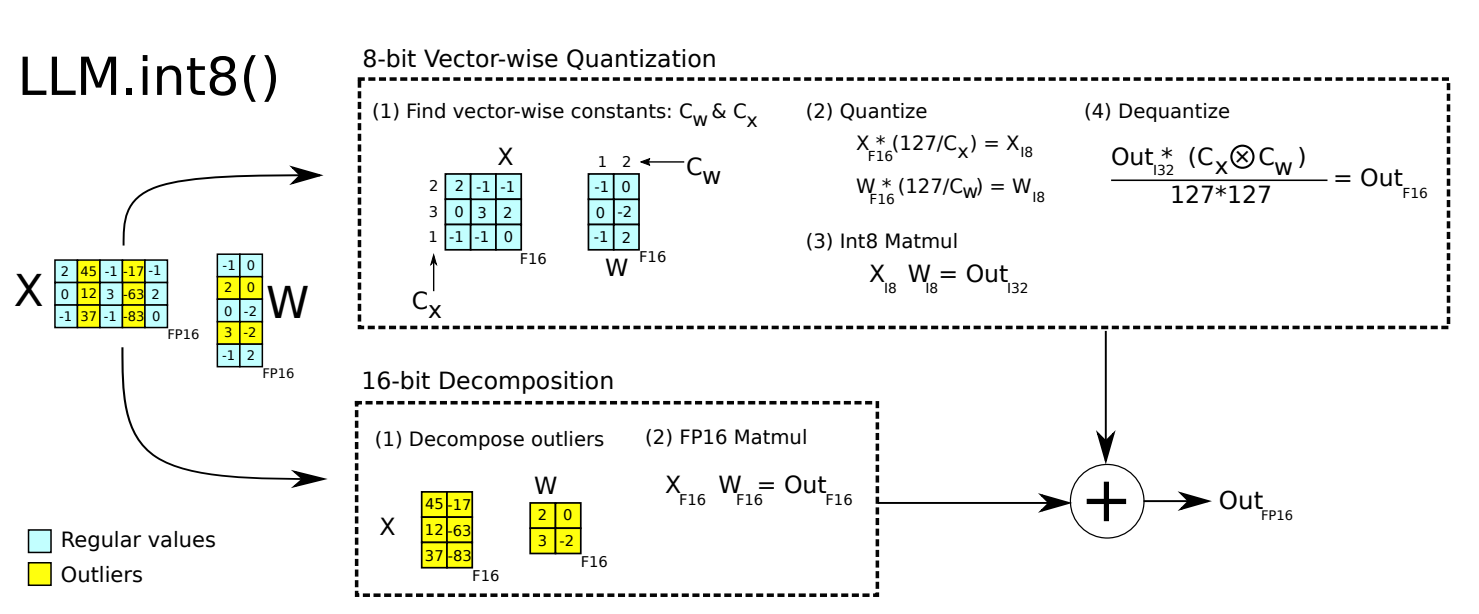
高亮部分为离群值,对于离群值不进行量化处理以fp16精度运算。对于非离群值则采用int8的方法进行量化。通过按行和列的绝对最大值$C_x$和$C_w$缩放,然后将输出量化为Int8,然后进行8位矩阵乘法再反量化。
(3) LLM.int8方法精度及效率
在精度方法:
如下图所示,作者在大小分别为125M,1.3B,2.7B,6.7B,13B的模型上使用不同的量化手段进行实验并评估各模型量化前后的困惑值。困惑值越低越好。
可以无论是传统量化方案的对称和非对称方法,精度都会有很大下降;但是相较于其他量化手段,经LLM.int8方法量化后的模型损失很小几乎与fp32的精度一致。
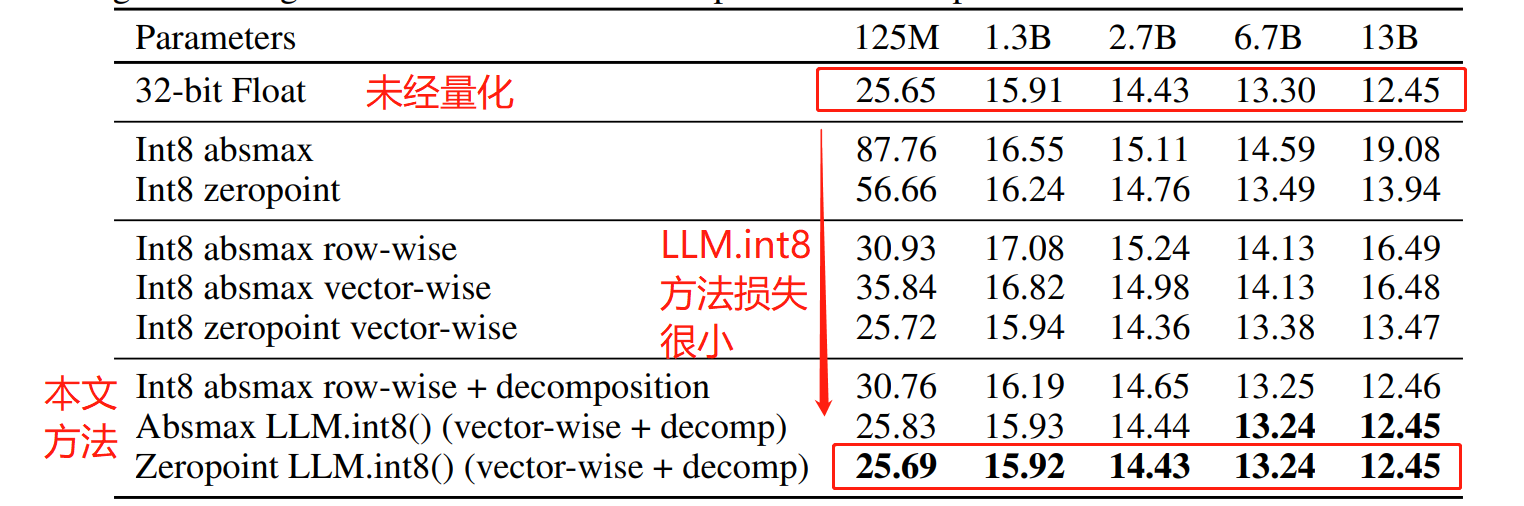
可以看到当模型增大到临界值时,常规的int8方法的精度出现了大幅下降。但是LLM.int8方法几乎没有下降。
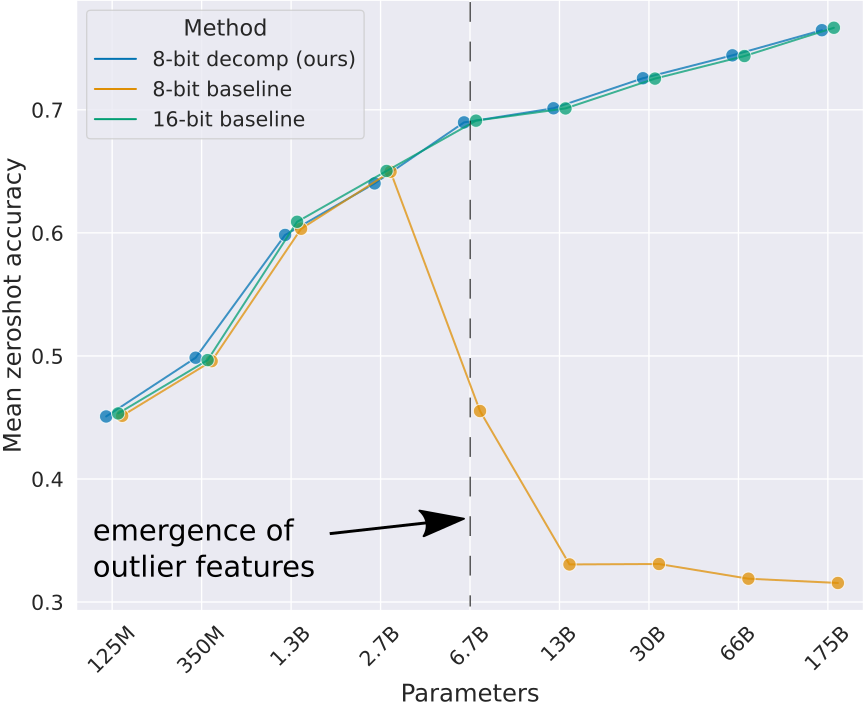
在速度方面:
目前关于速度方面的测试由两个来源一个是作者的博客,一个是论文。
博客:
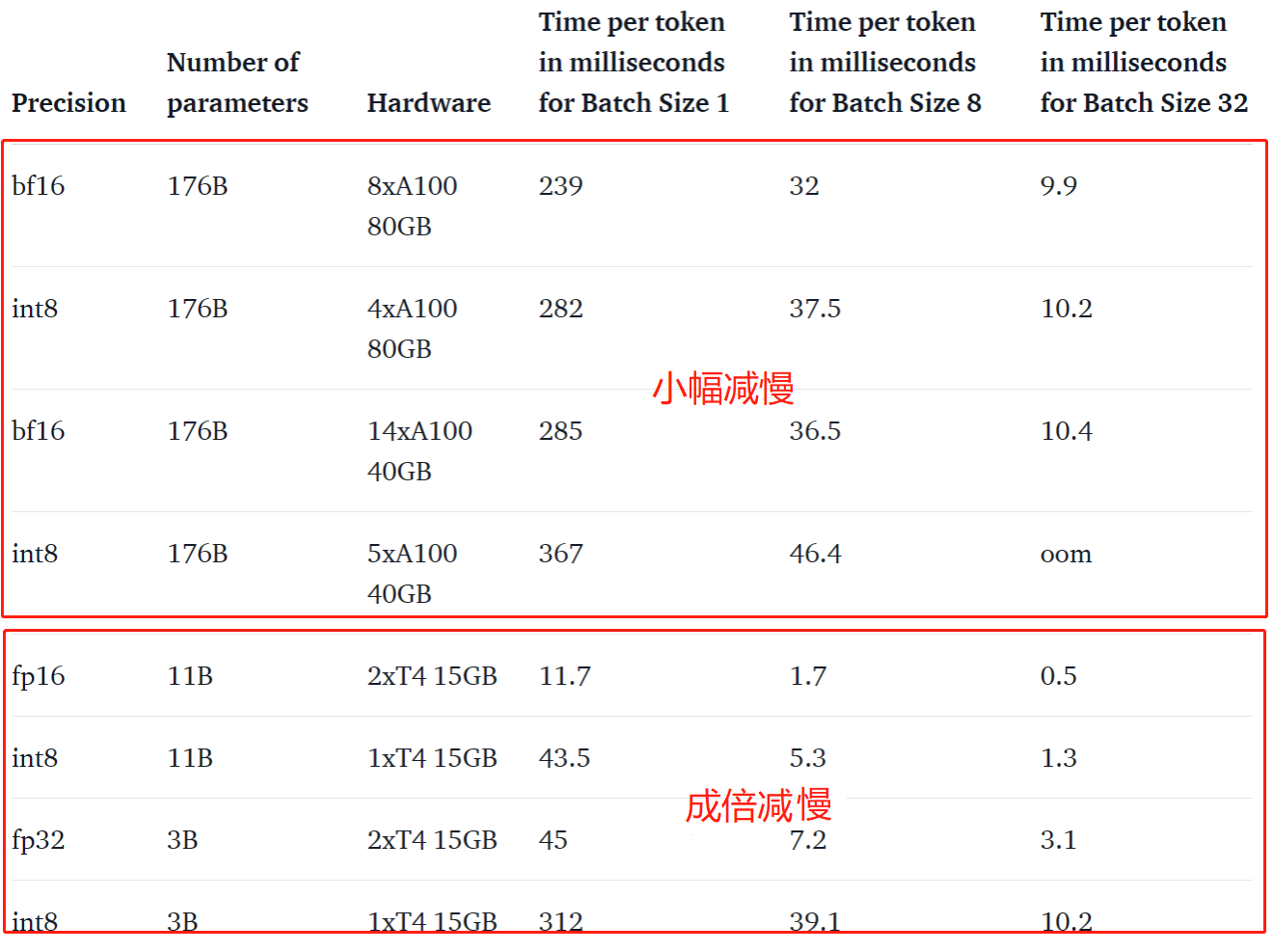
作者对比了不同模型大小下每个token的耗时(ms)。实验表明,使用LLM.int8的BLOOM-176B比fp16版本慢15%到23%,具体数据如下图。小模型部分成倍变慢。
作者提到在一天之内,他们将 T5-3B 的每词元推理延迟(左数第四列最底行)从 312 毫秒降低到 173 毫秒。也就是说本图中延迟的产生主要是算法的问题,作者团队目前正在优化中。
论文:
不同大小的模型在第一个隐藏层中16位矩阵乘法相较于baseline的速度。低于1.0x是变慢了。
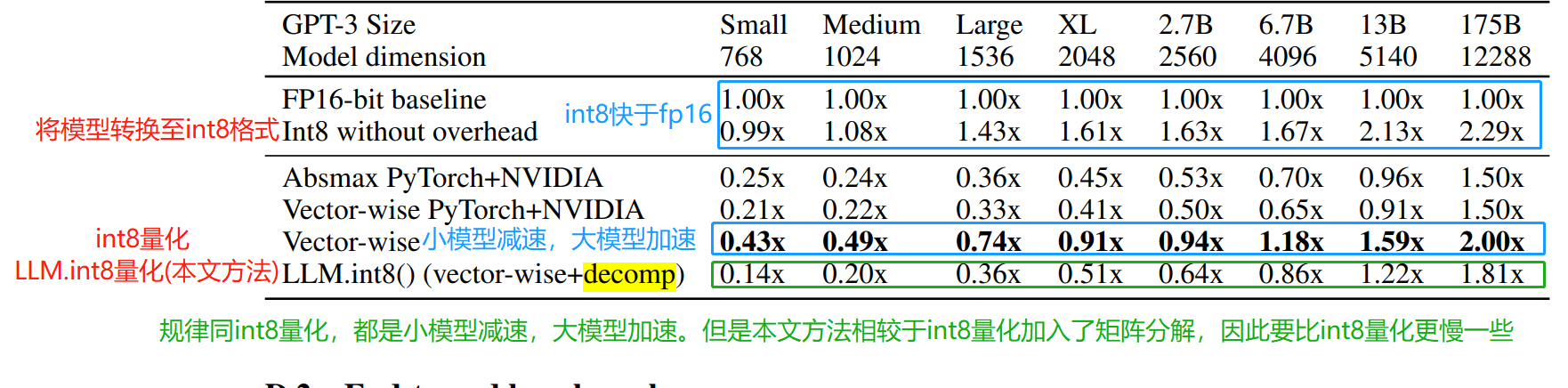
两种测量方法有共性也有区别,共性在于
- 无论是int8量化还是LLM.int8量化在速度上都是对大模型更友好
区别在于
- 在使用token测速的方法中使用了LLM.int8的方法速度要低于fp16。而在隐藏层中16位矩阵乘法的测速方法中,小模型的推理出现了明显的降速,而大模型的推理速度增加了。
显存方面

(4)实践
使用第三方库Linear8bitLt
import torch
import torch.nn as nn
import bitsandbytes as bnb
from bnb.nn import Linear8bitLt
fp16_model = nn.Sequential(
nn.Linear(64, 64),
nn.Linear(64, 64)
)
[... train the model ...]
torch.save(fp16_model.state_dict(), "model.pt")
int8_model = nn.Sequential(
Linear8bitLt(64, 64, has_fp16_weights=False),
Linear8bitLt(64, 64, has_fp16_weights=False)
)
# 此处标志变量 has_fp16_weights 非常重要。默认情况下,它设置为 True,用于在训练时使能 Int8/FP16 混合精度。但是,因为在推理中我们对内存节省更感兴趣,因此我们需要设置 has_fp16_weights=False。
int8_model.load_state_dict(torch.load("model.pt")) # 此时未进行量化
int8_model = int8_model.to(0) # 量化发生在此处
# 只有将模型加载至gpu中才会发生量化
input_ = torch.randn(64, dtype=torch.float16)
hidden_states = int8_model(input_.to(torch.device('cuda', 0)))
除了基础用法外,作者也给出了针对llama模型的示例代码。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 定义生成文本的最大长度
MAX_NEW_TOKENS = 128
# 设置使用的预训练模型名称
model_name = 'decapoda-research/llama-7b-hf'
# 定义待处理的文本
text = 'Hamburg is in which country?\n'
# 使用tokenizer将文本转换为模型可接受的输入格式(input_ids是模型接受的整数序列)
tokenizer = AutoTokenizer.from_pretrained(model_name)
input_ids = tokenizer(text, return_tensors="pt").input_ids
# GPU相关设置
free_in_GB = int(torch.cuda.mem_get_info()[0]/1024**3)
max_memory = f'{int(torch.cuda.mem_get_info()[0]/1024**3)-2}GB'
n_gpus = torch.cuda.device_count()
max_memory = {i: max_memory for i in range(n_gpus)}
# 参数load_in_8bit=True表示将模型以8位精度加载以减少内存占用
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map='auto',
load_in_8bit=True,
max_memory=max_memory
)
generated_ids = model.generate(input_ids, max_length=MAX_NEW_TOKENS)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
(5)Q&A
- 为什么经过量化后模型的推理速度变慢了?
因为在量化的过程中需要对矩阵进行拆分,这会导致推理速度变慢。
- 为什么小模型变慢的程度更大?
作者已经找到原因,主要是CUDA核的问题。概括来讲就是int8无法使GPU达到饱和因此速度和fp16一样,但是由于量化的过程需要额外开销就导致推理的速度降低了。理论上来讲一个6B的模型速度会提升20-40%左右。作者没法估计开销会拉低多少的速度因为开销更为复杂与sequence的长度,batchsize都有关系。
作者在半年前表示在后续版本中速度会更快。
- 离群值的数量与时空复杂度的关系是什么?
作者发现的几个现象与此问题有关,但是如问题2所述量化过程中开销的问题作者自己也没有想明白。
离群值涌现不是突然出现的而是渐进的,且与**困惑值(perplexities)**呈指数关系而与模型规模无关。
在发生phase shift之后,离群值开始迅速增长;
phase shift的意思是离群值突然在所有的层中出现并且开始相互协作。
(6)总结
方法较新,使用简单,精度几乎不会损失,可以有效降低显存。但是运行速度是否在可接受范围内需要进行实验。
(7)参考文献
作者Tim Dettmers的博客 : https://timdettmers.com/2022/08/17/llm-int8-and-emergent-features/
作者Younes Belkada的博客 :https://huggingface.co/blog/zh/hf-bitsandbytes-integration
B站博主米粒方糖的视频:https://www.bilibili.com/video/BV1Tx4y1d7sG/?spm_id_from=333.880.my_history.page.click&vd_source=3a72dc49e723efef59bcf133fb8fe42e
2. GPTQ量化(施工中)
只需要20G显存就可以把llama33B跑起来
由来自奥地利科技学院的Elias Frantar提出。目前该文章已发表在ICLR2023上。
论文:https://arxiv.org/pdf/2210.17323.pdf
Github(针对LLama版本):https://github.com/qwopqwop200/GPTQ-for-LLaMa
(1)方法介绍
经过从OBD到OBS到OBQ再到GPTQ。
待完善。
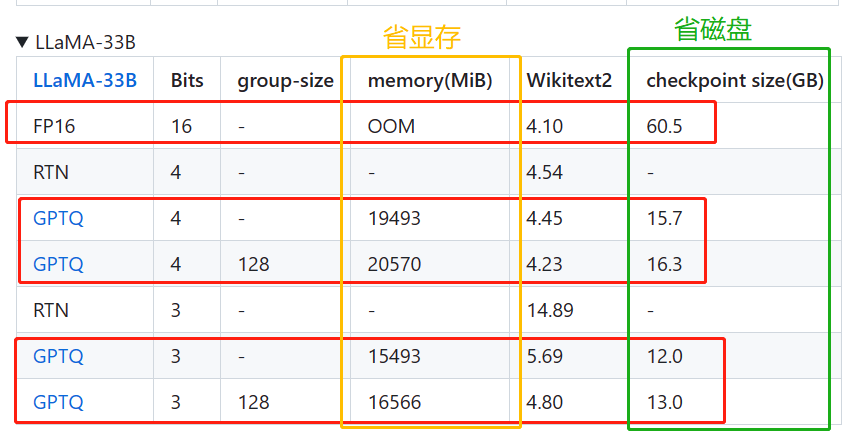
(2)在llama33B上的表现
实验在A100上进行。
(3)使用方法
python llama.py LLAMA_HF_FOLDER c4 --wbits 4 --true-sequential --act-order --new-eval
(4)与LLM.int8的区别
GPTQ是直接将fp16的模型量化成4bit的格式。而LLM.int8是读取fp16格式的权重然后将其加载到Linear8bitLt的层中,在转移至GPU后发生量化。
int8_model.load_state_dict(torch.load("model.pt"))
int8_model = int8_model.to(0) # 量化发生在此处
五. TODO
- 深入研究LLM.int8方法、
了解emergent feature现象https://arxiv.org/pdf/2208.07339.pdf
在论文《LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale》中int8 absmax和zeropoint具体是什么含义?
作者设计这种方法的灵感来自于哪里?
对于猜测“outliers”的存在是为了使模型提取特征是否成立?如果成立仅保留outliers会有多少的精度损失?能否设计一种方法保留一定比例的非outliers以平衡性能损失和模型对计算资源的占用?
llama.cpp背后的算法是什么?https://github.com/ggerganov/llama.cpp
通过阅读原论文及博客完善GPTQ的原理介绍 From 知乎 & arxiv
- 通过查看前人经验了解GPTQ & LLM.int8 使用方法 From youtube