论文解读 | LANGUAGE MODELS REPRESENT SPACE AND TIME
大模型中是否存在一个世界模型呢?
介绍
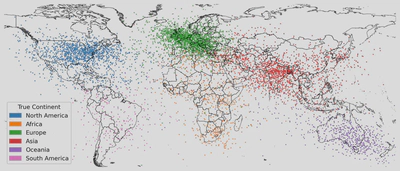
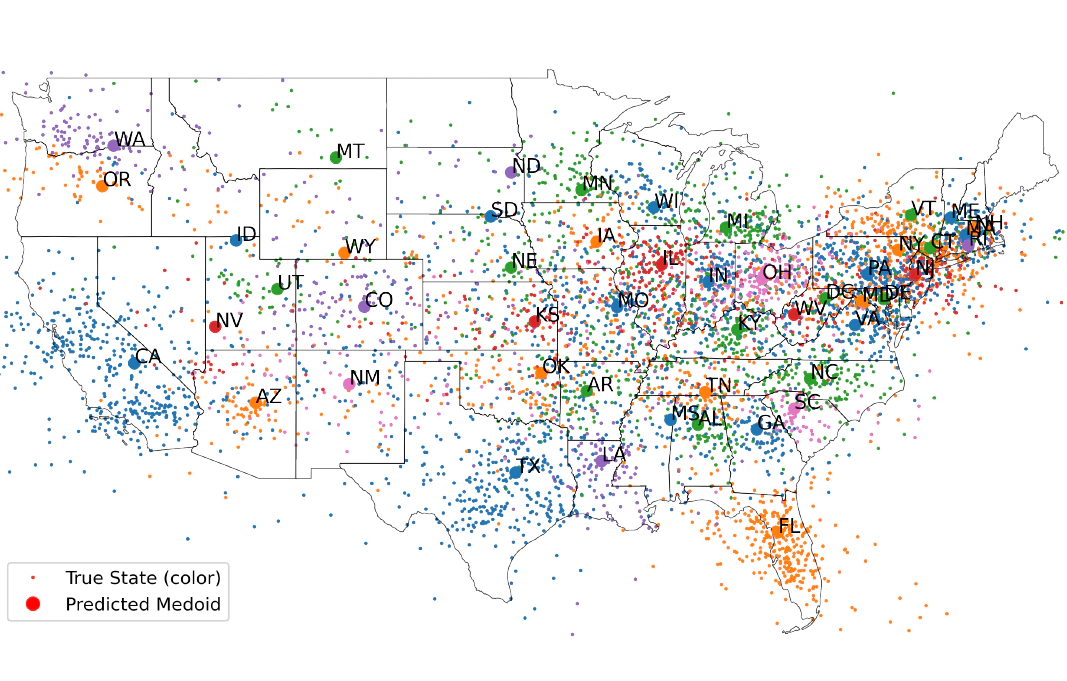
大语言模型诸多惊人的能力难道只是海量数据统计的结果吗?大语言模型的内部是否存在一个世界模型?近日,MIT的两位作者在Arxiv上发布的论文《LANGUAGE MODELS REPRESENT SPACE AND TIME》引发了学界的广泛关注。在这篇文章中,作者以llama2系列为实验对象,在自制的时空数据集上进行了实验,发现了后者存在的证据。
在这篇文章中作者产出了六个贡献,其中包含四个大贡献和两个小贡献。
主要贡献:
产出了三个空间数据集和三个时间数据集
证明LLMs对时空的表达是存在的且与模型、数据集有关
这种表达是线性的
这种表达对prompt的改变具有鲁棒性
鲁棒性检测
时间和空间神经元
第一个贡献是产出了六个数据集,工作量达标。
第二至四个贡献是侧面发现了LLMs内部存在世界模型的证据。在此之前,前人仅在小模型上进行过类似的实验。
第五个和第六个实验,笔者认为,是为了实验的严谨性和凑创新点。尤其是第六个,说存在”空间神经元“和”时间神经元“难免有搞噱头、博眼球之嫌。
为方便读者理解,在读者开始阅读之前,笔者需要对几个名词进行解释。
文中出现的“表达”在原文中是“representation”,笔者认为作者用这个词想表达的是LLMs内部隐藏层的状态。举例来讲,引述中提到的“LLMs对时间和空间的表达都是线性的”在原文中对应的实验为使用LLMs内部的隐藏层状态到$label$的映射是线性的。
文中出现的“实体”在原文中对应的是“entity”,这个词在原文中有“sample”之意,代表数据集中的一个样例。
文中玄乎的所谓的“世界模型”到底是什么?如果LLMs仅仅是对一段文字可能出现的下一个字进行预测,那么LLMs内部就不存在”世界模型“。反之,如果能找到LLMs内针对时空的结构化存储的证据,就可以说LLMs内部存在”世界模型“。
作者在本文中主要应用“探针”进行的实验,探针在原文中用“probe”表达。设输入为$X$,大模型输出为$Y$,隐藏层状态$h$。用$h$为feature,$Y$为label训练一个浅层小模型,这个浅层小模型就是探针——probe。
“时空”是对“时间和空间”的简写。在本文中空间的表达有“spatial“和”space“,时间的表达有”temporal“和”time“
论文解析
摘要
大语言模型(LLM)的领军位置引发了大模型系统到底只是对海量数据进行肤浅地统计还是真正学习到了世界模型的争论。在本文,作者以llama2为实验对象,在三个空间数据集和三个时间数据集上进行了实验发现了后者存在的证据。作者发现不同参数量的LLMs对时间和空间的表达都是线性的;LLMs对时间和空间的表达对prompt的改变具有鲁棒性;这些表达是跨实体类型的(例如城市和地标);发现了“空间神经元”和“时间神经元”。
起因
虽然LLMs的出现引发了世界各界的广泛关注,但是人们对LLMs内部的细节理解十分有限。LLMs的运行过程是对海量数据进行统计还是经过思考的,自LLMs诞生起就争论不休。
在本文,作者从时间和空间的角度试图解释这个问题。
准备工作
数据集
作者创建了六个数据集,其中三个是空间数据集,三个是时间数据集。对于每一个数据集中的每个实体,由一个名字和对应位置或时间构成的。三个空间数据集分别由世界、美国、纽约的地名构成。三个时间数据集分别由历史人物、作品、新闻构成。
| 数据集 | 样例 |
|---|---|
| 世界 | 洛杉矶,圣彼得堡,里海 |
| 美国 | 芬威球场,哥伦比亚,河滨县(位于加州) |
| 纽约 | 波登大道大桥,特朗普国际酒店 |
| 人物 | Cleopatra(埃及艳后),Dante Alighieri(但丁),Carl Sagan(卡尔·萨根) |
| 作品 | 小丑回魂,波西米亚狂想曲 |
| 新闻 | 略 |
模型
llama2 family
激活数据集
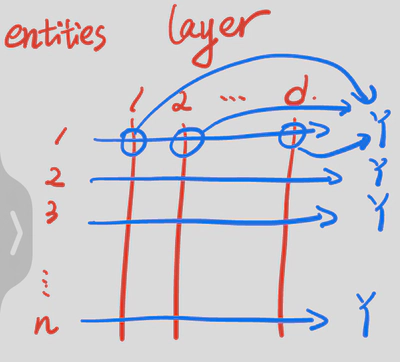
设某数据集中具有n个实体,LLM有$d_{model}$层。那么将n个实体分别输入LLM,在各隐藏层检测激活状态并记录,即可获得激活状态数据集$A\in\mathbb{R}^{n\times d_{model}}$。
探针
作者将地名或人名等作为输入$x$输入大模型$model$。用隐藏层状态$h$作为$feature$,用$x$对应的$y$作为$label$,训练探针,并在测试集上测试探针的性能。
Understanding intermediate layers using linear classifier probes. Probing classifiers: Promises, shortcomings, and advances.
评估标准
$R^2$ & Spearman rank
主要实验设计及结果
1. LLMs内部是否存在针对时空的表达?如果有,在哪里?跟模型的参数量是否有关系?
作者用从自制六个数据集得到的六个激活状态数据集训练探针,然后将探针在测试集上进行实验,获得了探针在不同参数量的LLM上、不同层深度上、不同数据集上的精度。
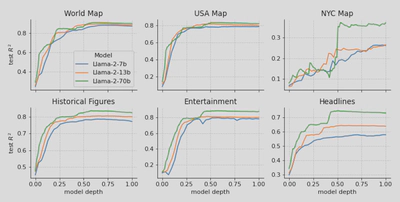
作者从上图得到了五个发现。
时空feature都可以被线性探针拟合
模型参数量越大,探针精度越高
在前50%层精度平滑上升
在三个空间数据集中,NYC的表现最差。作者猜测是因为NYC的地图范围较小,很多的地名都是默默无闻的,因此大模型不认识
在NYC地图中,模型参数量带来的精度差距最为明显
笔者认为从逐步上升的曲线就可以看出,模型内部关于时空信息的表达是有一定结构性的规律的,以至于可以被探针学习到。同时,第四个和五个发现侧面印证了模型内存在知识库或存储库的可能。如果这个可能可以被证实,大模型或许可以作为一种数据压缩的手段。
2. LLMs对时空信息的表达是否是线性的?
作者在这里首先叠了一下甲,阐明自己相比前人的创新点。作者说虽然前人有一些工作证明在神经网络内部线性表达的假说,但是前人的工作是针对二分类或多分类等离散任务的,而本文任务的label是连续的。
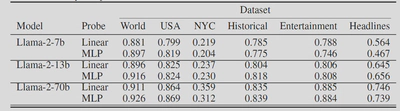
作者分别训练简单的线性探针和非线性的MLP探针并在测试集上进行测试,对比上图发现两个探针的精度差异几乎不存在。对一个映射关系$f$,如果它是线性的,那么线性模型和非线性模型都可以很好地拟合且性能差距较小。如果它是非线性的,那么线性模型拟合效果要差于非线性模型。因此作者认为$h$到$label$的映射关系是线性的。也就是文中所说的“LLM对时间和空间的表达是线性的”。
3. 对prompt的敏感性
为了验证时空表达对prompt的变化是否敏感作者设计了此实验。
对于除新闻外的五个数据集,作者设计了如下四种prompt。
empty:无其他prompt
coords/when:添加“What is the latitude and longitude of
” or “What was the release date of ’s .”等描述性和消歧性的prompt和几乎不会降低性能 baseline:添加10个随机tokens
all_cap:全大写
新闻数据集,作者设计了如下四种prompt。
empty prompt
加句号
添加述性和消歧性的prompt
添加述性和消歧性的prompt的基础上加句号
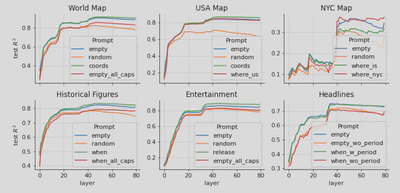
观察上图,作者发现如下现象
empty和添加述性和消歧性的prompt在精度上几乎没有区别
baseline的精度很低,random tokens可以显著降低精度
大写也会降低精度,但是并不令人吃惊,因为已经有前人的发现了此现象
新闻数据集中加句号可以显著提高精度
整体而言,时空表达对prompt具有相当的鲁棒性。
不足
作者在结尾提到本文还存在一些不足
可以使用离散的编码器来提取模型的时空表达
在数据集中并不是所有的实体大模型都认识,按理说应该剔除
读后感
笔者读完的第一个感受就是”就这?“,虽然本文在贡献和创新上都比较突出,但是和媒体宣传的”世界模型“相比,难免有”标题党“之嫌。当然,当”标题党“未必是作者的本意,也可能是有些媒体为了蹭热度而为。
在贡献上,光数据集的收集、制作、整理就满足一篇顶会的工作量,更不用说将探针部署在多个LLM的每一层上,在工作量上相比起同类论文足以遥遥领先。在创新上,本文并没有在方法上太大的创新,而是将过去小模型上的常规手段搬到大模型上。本文的发现虽然没有标题党们宣传的那么玄乎,但是LLMs对时空的线性表达这一发现足以满足一篇顶会论文的创新性。
在内容上,本文是一篇标准的”实验报告“,没有数学证明也没有公式推导,有的只有设计实验、进行试验、结果分析。
在语言上,本文的用词和写作很讲究。笔者作为一个中国人读起来比较吃力,和读中国人写的文章感受完全不同。
综上,本文是一篇远超顶会及格线的论文,但是达不到标题党们宣传的证明”世界模型“的标准。