Reward and Guidance through Rubrics: Promoting Exploration to Improve Multi-Domain Reasoning
Abstract:
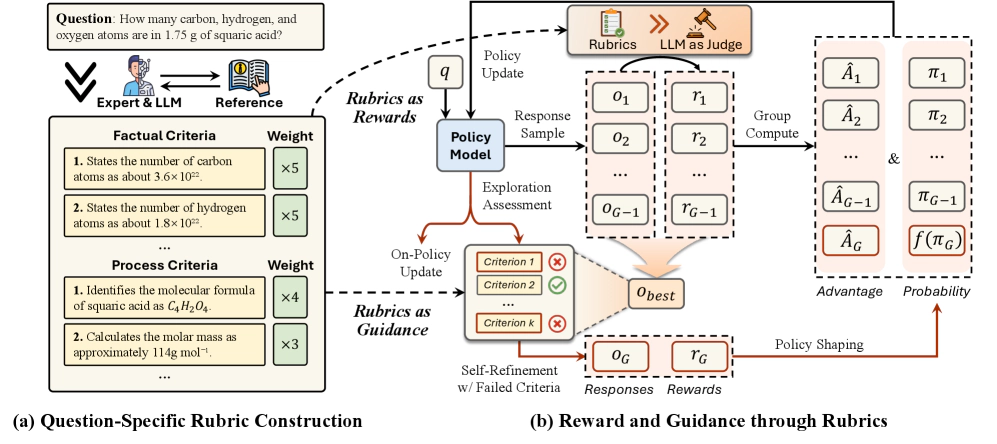
Reinforcement learning (RL) has shown great promise in enhancing LLM reasoning, but current approaches mainly focus on single domains with verifiable rewards. We propose RGR-GRPO, a rubric-driven RL framework for multi-domain reasoning that uses rubrics to provide fine-grained reward signals and offline guidance. This approach helps LLMs receive dense and informative rewards while exploring a larger solution space during GRPO training. Experiments across 14 benchmarks show RGR-GRPO outperforms alternatives, achieving average gains of +7.0%, +5.4%, +8.4%, and +6.6% on math, physics, chemistry, and general reasoning tasks respectively. The method also maintains stable entropy fluctuations during off-policy training and demonstrates stronger pass@k performance, indicating sustained exploration capabilities.